
Comment optimiser son RAG ?
Si vous êtes arrivé ici, c'est que vous avez déjà un minimum de compréhension sur les RAG : à quoi ils servent, comment ils fonctionnent et quels sont les enjeux. Si ce n'est pas le cas, je vous invite à venir découvrir cet article sur une introduction aux RAG ! Dans cet article, on va découvrir comment optimiser un RAG, ou en clair, quels sont les leviers qui permettent à un RAG de répondre au mieux aux questions qui lui sont posées.

1 - Optimisation RAG : Par où commencer ?
Avant de chercher à optimiser son RAG, il faut déjà se poser la question Qu'est-ce qui ne va pas avec mon RAG ? Est-ce que ses réponses sont à coté de la plaque ? Qu'il ne trouve rien ? Qu'il hallucine ?
Une fois que vous aurez des réponses à ces questions, vous saurez comment axer vos optimisations, et surtout, ça vous permettra de savoir quand les optimisations auront vraiment un impact sur votre RAG.
Dans tous les cas, les optimisations seront faites principalement à 3 endroits différents :
- Indexation
- Récupération
- Génération
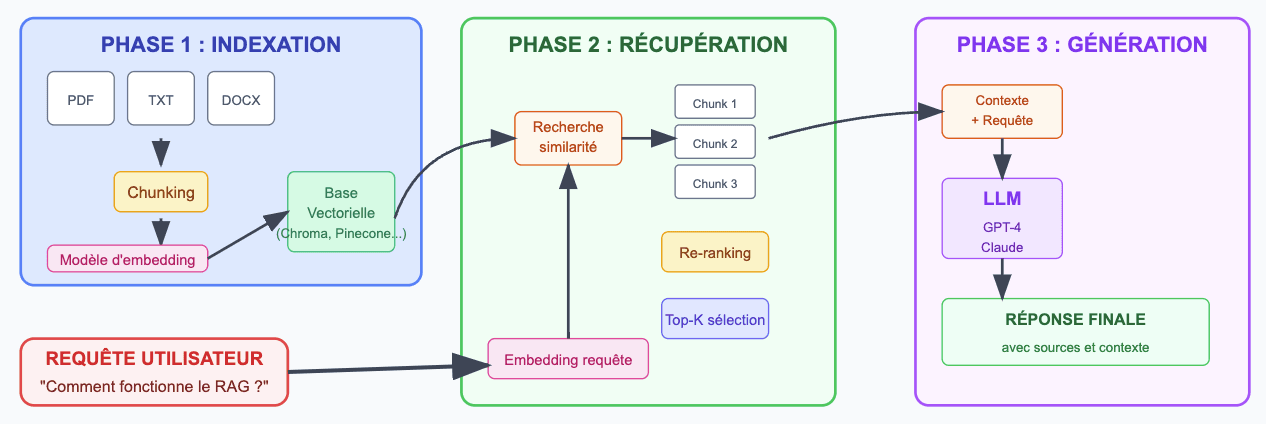
Les phases les plus importantes sont les 2 premières : phase d'indexation et de récupération ! Plus les données que vous tirerez de la phase d'indexation seront riches et bien catégorisées, plus loin vous pourrez pousser votre récupération, et donc meilleure sera votre génération!
2 - Optimiser son RAG, c'est d'abord optimiser ses chunks !
La différence entre un bon et un mauvais chunk ?
Le chunk, c'est la pierre angulaire d'un bon RAG. S'ils sont mal découpés, peu pertinents, qu'il ne contiennent pas assez ou trop de contexte, c'est tout le RAG qui s'écroule. Il est donc indispensable de s'assurer d'avoir les meilleurs possibles, mais pour cela, on peut se demander Qu'est-ce qu'un bon chunk ?
Un bon chunk, c'est entre autre :
- Une unité de sens complète et autonome
- Une taille optimale - en général entre 200 et 500 tokens. Il doit être assez court pour être pertinent, mais assez long pour fournir un contexte suffisant au LLM. En fonction des besoins du RAG, on peut décider d'avoir des chunks plus petits (pour une recherche précise), ou plus grands (pour une meilleure compréhension globale)
- Un overlap entre chunks consécutif - l'idée est de chevaucher les chunks qui se suivent sur celui d'avant et d'après. Cela permet de préserver le contexte entre chunks, et d'éviter la perte d'informations.
- Adapté au type de contenu - par exemple pour une documentation technique, on fait attention à garder les problèmes/solutions ensemble, ou pour du code, de garder les fonctions entières.
- Des métadonnées pertinentes - le point le plus important d'un bon chunk : des métadonnées riches et utiles ! Elles servent à enrichir vos chunks, et leur donner du contexte qui n'est peut être pas dans le contenu.
Pour ce dernier point, voici quelques métadonnées indispensables :
- Source du document, page, sections
- Date, auteur, version
- Tags, type de document
Maintenant qu'on a vu les bases d'un bon chunk, on peut explorer des pistes un peu plus complexes quant à l'optimisation de la phase d'indexation pour votre RAG.
Proposition chunking pour optimiser son RAG
Plutôt que de découper les documents selon des critères structurels classiques (paragraphes, phrases..), cette méthode décompose l'information en propositions. Une proposition encapsule un fait unique et complet, capable d'être compris sans contexte externe.
Par exemple, un paragraphe sur la Seconde Guerre mondiale serait transformé en propositions distinctes comme "La Seconde Guerre mondiale a commencé le 1er septembre 1939" ou "Ce conflit oppose les Alliés et l'Axe".
Cette granularité fine résout plusieurs problématiques des méthodes traditionnelles : elle évite la dispersion d'informations importantes sur plusieurs chunks, élimine le bruit en isolant chaque fait pertinent, et permet un ciblage précis lors de la recherche.
Le proposition chunking s'avère particulièrement efficace pour les systèmes nécessitant une haute précision factuelle et la capacité de répondre à des questions complexes nécessitant l'agrégation de multiples faits spécifiques.
HyPE - Hypothetical Prompt Embeddings
Le principe est simple, plutôt que de chercher à établir une similarité entre une question (formulée par l'utilisateur) et un texte (le contenu du document), HyPE transforme le problème en une comparaison question-question.
Concrètement, lors de l'indexation, le système génère plusieurs questions auxquelles chaque chunk pourrait répondre. Par exemple, pour un chunk expliquant "L'ibuprofène est un anti-inflammatoire non stéroïdien qui agit en inhibant les enzymes COX-1 et COX-2, réduisant ainsi la production de prostaglandines responsables de l'inflammation et de la douleur.". HyPE générerait des questions comme "Comment fonctionne l'ibuprofène ?" ou "Pourquoi l'ibuprofène réduit il la douleur ?"
Au moment de la requête, la question de l'utilisateur est comparée à ces questions plutôt qu'au texte source, permettant une correspondance plus précise.
HyPE s'avère particulièrement efficace pour les systèmes où les utilisateurs posent des questions sur des corpus techniques ou académiques au style formel.
3 - Une meilleure recherche
La base d'une bonne recherche étant la qualité de la requête, on peut facilement imaginer utiliser un LLM avant la recherche, afin d'extraire certaines informations de la requête utilisateur, ou de la reformuler afin qu'elle soit plus adaptée à une recherche vectorielle.
Par exemple, pour une requête "Quelle est l'échelle des impôts pour cette année ?", un LLM pourrait extraire l'année et comprendre le vrai sens de la phrase malgré l'utilisation du mauvais vocabulaire, et reformuler en "Barème des impôts année 2025".
Un point important à noter également est le nombre de chunks retournés lors d'une recherche.
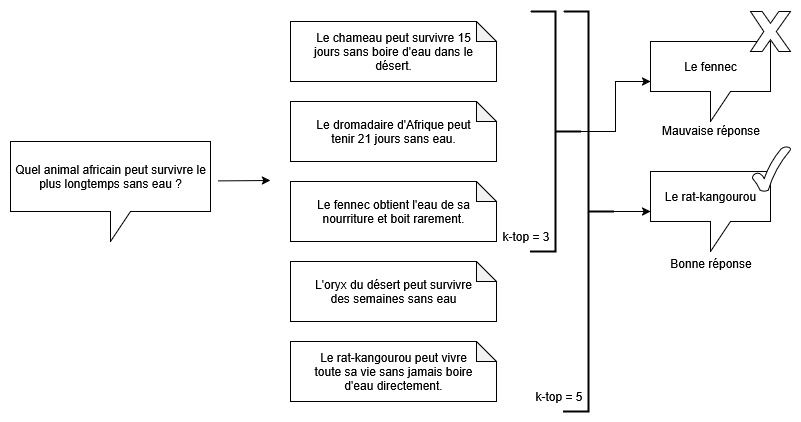
Comme vous pouvez voir dans l'exemple ci-dessus, avec un k-top à 3, une mauvaise réponse est donnée, car la vraie bonne réponse se trouve dans un chunk plus bas dans la liste.
Il est donc crucial de toujours bien avoir en tête ces limitations, avant même de penser à faire des optimisations complexes.
Re-ranking
Un principe plutôt simple : une fois la recherche effectuée, les chunks trouvés sont envoyés dans une nouvelle brique appelée "reranker", qui a pour but de les trier par ordre de pertinence.
Comme vu plus haut, une des problématiques avec la recherche vectorielle, est que, ne connaissant pas vraiment le contenu de chaque vecteur, on se retrouve avec des résultats qui sont rarement triés par pertinence, et donc, avec le risque que les informations les plus importantes se trouvent plus bas dans la liste. Vous me direz que tant pis, au pire, on a qu'à augmenter le nombre de chunks passés à la génération... Mais rajouter du contexte inutile ne ferait que réduire la qualité de la réponse, sans parler du coût qui exploserait...
C'est là que le reranker fait son entrée ! On va bien augmenter le nombre de chunks retourné par notre recherche vectorielle, mais on va les passer dans le reranker, qui va les trier par ordre de pertinence, pour ne ressortir que les K premiers.
Imaginez une recherche du type "Tu peux me donner les enfants du roi de France de 1900". La recherche vectorielle va peut être trouver 50 chunks qui parlent des rois de France. Avec une recherche K classique, si vous ne récupérez que les 10 premiers chunks, vous n'aurez pas forcement la bonne réponse. Avec un reranker, il va trier les chunks pour mettre en premier tous ceux qui correspondent le plus à votre requête.
Le re-ranking est une technique très efficace pour optimiser votre RAG, mais elle vient avec un coût et un temps de réponse plus grand.
Query Expansion
Le Query Expansion consiste à générer plusieurs autres questions similaires à celles formulées par l'utilisateur. En plus de reformuler les questions qui pourraient être mal tournées, cette technique peut aussi permettre de couvrir un plus grand nombre de mots clés, ce qui est très utile pour la recherche vectorielle.
Par exemple, imaginez la requête "J'ai mal au ventre". Le Query Expansion pourrait générer "douleur abdominale", "maux de ventre", "douleurs intestinales", "problèmes gastriques", "troubles digestifs douloureux".
C'est une technique assez simple à mettre en place, et qui peut facilement améliorer la pertinence des chunks retournés, et donc des réponses de votre RAG.
4 - La génération
La phase de génération est la partie la plus complexe à optimiser dans le RAG, les LLM fonctionnant déjà très bien. Cependant, on peut toujours pousser leur utilisation, afin d'avoir de meilleurs résultats !
Interactive Retrieval
On ne peut pas s'assurer que tous les utilisateurs sachent parfaitement formuler une requête à son RAG, et, honnêtement, même une personne aguerrie peut oublier des détails importants. Une solution simple consiste à demander plus de précisions à l'utilisateur.
Si je demande "Quel est le barème des impôts ?", la recherche vectorielle me retournerait les barèmes toutes années confondues, et la génération ne pourrait pas répondre correctement. C'est à ce moment là qu'on pourrait demander à l'utilisateur "De quelle année ?", pour ensuite ajouter la réponse dans le contexte de la génération afin d'affiner la réponse.
On pourrait aussi imaginer que les questions soient posées avant la recherche vectorielle, afin d'être encore plus précis sur les chunks utilisés pour la génération de la réponse.
Fine Tuning
Pour des RAG portant sur des sujets très spécifiques, le fine-tuning peut être une solution pour réduire les hallucinations. En effet, si vous voulez un RAG qui répond uniquement à des questions sur du Droit, utiliser un modèle fine-tuné pourrait lui permettre d'éviter de "penser" à autre chose lors de vos questions, et de rester dans le droit chemin.
Toutefois, le fine-tuning est un processus complexe et coûteux, et ne devrait être envisagé qu'en toute fin d'optimisation, quand vous avez déjà tout le reste de la chaine qui est au top !
D'autres manières d'optimiser son RAG ?
Honnêtement, il existe des dizaines de façon d'optimiser son RAG, et en fonction des besoins, les techniques seront bien différentes ! Nous avons essayer ici de vous donner un aperçu de certaines de ces techniques, en particulier, celles qui nous paraissent les plus pertinentes et intéressantes à connaitre, mais elles sont loin d'être exhaustives. Je le pose ici mais si jamais vous avez besoin d'aide pour mettre en place ou optimiser votre RAG, notre équipe peut vous aider !
Partagez-nous vos retours d'expérience sur les RAG, on est curieux de vous lire sur le sujet !
Nos podcasts en lien


Pour aller plus loin
AWS SAM - l'outil IaC d'AWS dédié au serverless
AWS SAM : "Simplify Serverless", telle est la devise qu'Amazon nous propose pour son Framework d'Infrastructure as Code (IaC) dédié au Serverless ! La promesse est-elle tenue ? Est-ce un concurrent ou un allié des outils déjà existants comme Terraform ? C'est ce que nous allons tenter de découvrir dans cet article !
Clustering TOMCAT et MULTICAST
Tomcat 7 offre des solutions de clustering performante et simple d’utilisation. Retour d’expérience sur la mise en place des adresses MULTICAST
PME et ETI : Pourquoi votre système d'information est votre plus grand frein à la croissance ?
Dans les PME et ETI en croissance rapide, le système d'information est rarement une priorité, jusqu'au jour où il devient un problème. Cyberattaque, impossibilité de traiter les commandes, données non fiabilisées… Les signaux d'alerte s'accumulent, sont ignorés, jusqu'au point de rupture.




Nous suivre, nous écouter





