
La performance des applications
Une application offrant des performances médiocres peut ralentir la productivité des collaborateurs et entrainer frustrations et stress jusqu’au rejet total de l’application par les utilisateurs. Un projet informatique est réussi uniquement lorsque l’appl
Une application offrant des performances médiocres peut ralentir la productivité des collaborateurs et entrainer frustrations et stress jusqu’au rejet total de l’application par les utilisateurs. Un projet informatique est réussi uniquement lorsque l’application qui en découle est réellement utilisée par les équipes et permet de répondre aux enjeux métiers.
video: https://www.youtube.com/embed/dvkYfoTjGJU
1) Définition de la notion de performance dans un SI
Au niveau d’un système informatique la performance ne se définit pas uniquement par les temps de réponse résultants des applications aux utilisateurs, cette notion est plus vaste et comprend les aspects suivants :
- Les temps de réponse (respond time)
- La disponibilité du système (availability)
- La robustesse (robustness)
- La capacité de montée en charge (scalability)
Les temps de réponse
Un temps de réponse désigne la durée d’exécution d’une opération sur le système informatique. Cette opération, par exemple l’affichage d’une page Web de présentation d’un article, peut recouvrir l’invocation de plusieurs composants logiciels (serveur web, serveur d’application, serveur de base de données etc…).
Des temps de réponse non conformes aux attentes impliquant des ralentissements visibles par les utilisateurs peuvent entrainer une mauvaise acceptation voire un rejet dans certains cas de l’application ou du site Web.
La disponibilité du système
La disponibilité d’un composant du système informatique désigne le ratio de temps pendant lequel il est en état de fonctionner correctement sur une période de temps donnée (figure ci-dessous). La disponibilité s’exprime en pourcentage, elle est notée A ou HA en Anglais (pour Availability ou High Availability).
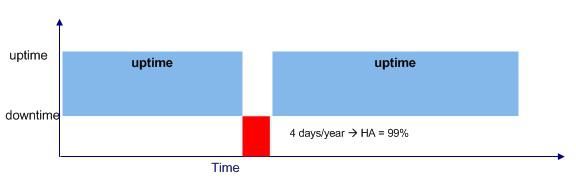
Les applications d’entreprise ont généralement une disponibilité de 90% à 95%. A partir de 99% on parle d’architecture à « haute disponibilité ».
La disponibilité peut concerner :
- Une application ou un service ;
- Un équipement matériel (serveur, baie de stockage, etc…) ;
- Un équipement réseau (routeur, répartiteur de charges, etc…) ;
- Un îlot applicatif ou une plateforme complète ;
On parle de « tolérance aux pannes » (fail over) pour un système qui peut fonctionner lorsqu’un de ses composants est défaillant et peut être remplacé à chaud, c’est-à-dire sans arrêt du service.
La robustesse
La robustesse désigne la capacité d’un système à ne pas « planter » et « perdre ou corrompre » des données ou des messages lorsqu’il est soumis à des sollicitations inhabituelles. Il s’agit donc d’une mesure de la disponibilité des systèmes et de l’intégrité des informations en situation de stress.
L’intégrité peut se porter sur :
- Des données échangées avec d’autres systèmes (messages, fichiers, etc.) ;
- Des données persistantes stockées dans des bases de données, annuaires, serveurs de fichiers, etc.
La robustesse s’exprime par une grandeur scalaire sans unité, par exemple :
- Pas plus d’un message perdu pour 100 000 messages traités ;
- Au maximum trois redémarrages d’un serveur de base de données par mois ;
La capacité à monter en charge
La capacité à monter en charge désigne l’aptitude d’une application ou d’un service à offrir des temps de réponse « raisonnables » quand la quantité d’utilisateurs simultanés augmente.
La capacité à monter en charge s’exprime par « une durée maximum de traitements pour un niveau de charge donné ». C’est-à-dire un temps de réponse pour un volume de charge. On parle aussi de débit ou throughput, mesuré en nombre de tâches simultanées par unité de temps.
Par exemple :
- 3 secondes maximum pour afficher une page Web avec 100 utilisateurs simultanés sur le site ;
- 3h30 maximum pour traiter les factures des 10 000 clients en base de données.
La capacité à monter en charge est une caractéristique tout aussi importante que les temps de réponse car elle précise le contexte dans lequel ceux-ci doivent être atteints.
Pour connaître l’état de votre application, réalisez un audit de performance !
2) La mesure des performances d’un SI
Un test de performance est un test dont l’objectif est de mesurer la performance d’un système informatique par rapport aux contraintes et exigences identifiées au début du projet (temps de réponse maximum admissible par page, nombre d’utilisateurs simultanés…).
Pour mesurer les performances des applications constituant un SI, il est possible d’effectuer les tests suivants :
- Test de charge : Lors de ce type de test on simule l’utilisation progressive de l’application par un nombre d’utilisateurs jusqu’à arriver à x fois le nombre d’utilisateurs cibles et ainsi valider l’application pour une charge attendue d’utilisateurs en ayant tout de même une certaine marge de sécurité. Ce type de test permet de mettre en évidence les points sensibles et critiques de l’architecture technique. Il permet en outre de calculer le dimensionnement (sizing) des serveurs ainsi que de la bande passante réseau nécessaire pour la mise en production de l’application.
- Test de performance : A l’instar du test de charge, lors des tests de performances nous allons simuler un certain nombre d’utilisateurs et mesurer chacune des étapes constituant le temps de réponse final constaté par l’utilisateur grâce à des sondes techniques positionnées sur chacun des composants de l’architecture (base de données, serveur d’application, accès disque, réseau…). Ces tests permettent de ventiler le temps total de traitement d’une page entre les différents composants de l’architecture et ainsi proposer des axes d’amélioration de l’application lorsque l’on n’obtient pas de celle-ci les performances escomptées.
-
Test de dégradations des transactions : il s’agit d’un test technique primordial au cours duquel on ne va simuler que l’activité transactionnelle d’un seul scénario fonctionnel parmi tous les scénarios du périmètre des tests, de manière à déterminer quelle charge limite simultanée le système est capable de supporter pour chaque scénario fonctionnel et d’isoler éventuellement les transactions qui dégradent le plus l’ensemble du système.
-
Test de stress : il s’agit d’un test au cours duquel on va simuler l’activité maximale attendue tous scénarios fonctionnels confondus en heures de pointe de l’application, pour voir comment le système réagit au maximum de l’activité attendue des utilisateurs.
-
Test de robustesse, d’endurance et de fiabilité : il s’agit de tests au cours duquel on va simuler une charge importante d’utilisateurs sur une durée relativement longue, pour voir si le système testé est capable de supporter une activité intense sur une longue période sans dégradations des performances et des ressources applicatives ou système.
-
Test de capacité, test de montée en charge : il s’agit d’un test au cours duquel on va simuler un nombre d’utilisateurs sans cesse croissant de manière à déterminer quelle charge limite le système est capable de supporter.
-
Test aux limites : il s’agit d’un test au cours duquel on va simuler en général une activité bien supérieure à l’activité normale, pour voir comment le système réagit aux limites du modèle d’usage de l’application.
Il existe d’autres types de tests, plus ciblés en fonction des objectifs à atteindre dans la campagne de test.
Pour pouvoir calculer la disponibilité d’un système, il est nécessaire d’utiliser les notions suivantes :
-
L’uptime désigne le temps de bon fonctionnement d’un système ou temps écoulé depuis le dernier démarrage ou le dernier « plantage ».
-
Le MTBF (Mean Time Between Failure) est le temps moyen entre deux « plantages » pour un composant d’architecture.
-
L’AFR (Annualized Failure Rate) est l’inverse du MTBF rapporté à une année, c’est-à-dire qu’il représente la proportion de composants à changer chaque année.
-
Le downtime désigne le temps d’arrêt lié à un dysfonctionnement.
-
Le MTTR (Mean Time To Repair) désigne le temps moyen nécessaire au rétablissement du service.
-
L’AST (Agreed Service Time) désigne l’exigence de continuité de service convenue avec les utilisateurs du système.
Sur la base de ces définitions, on peut calculer la disponibilité de trois manières :

Quand à la robustesse d’un système, elle est constatée en production en réalisant un ratio entre le nombre de sollicitations traitées par un composant (requêtes) et le nombre d’erreurs obtenues.
3) Les coûts induits par la recherche de la performance
Plus l’on souhaite obtenir un système informatique performant, plus le coût engendré par cette exigence devient important. On estime en informatique que le coût de la performance d’un système répond à une fonction exponentielle.
Il est donc primordial avant tout de déterminer quel est le niveau d’exigence d’une application en terme de performance avant de démarrer tout projet informatique, et d’autant plus, toute campagne de test de performance.
Sur le plan de la disponibilité des systèmes, l’atteinte d’un très haut niveau de disponibilité est très coûteuse en termes de matériel, de logiciels et de surveillance humaine. Le surcoût engendré par cette recherche du meilleur taux de disponibilité doit être mise en relation avec les coûts engendrés par une indisponibilité du système (cf. tableau ci-dessous).
| Secteur d’activité | Coût moyen par heure |
|---|---|
| Banque d’investissement | 6,48 M$ |
| Télécom | 2,00 M$ |
| Web marchand | 1,1 M$ |
| Pharmacie | 1,0 M$ |
| Chimie | 0,7 M$ |
| Réservation aérienne | 90 k$ |
Nos podcasts en lien


Pour aller plus loin
Les tests unitaires en Java Springboot
Pourquoi et comment écrire des tests unitaires ? Définition et implémentation dans une application Java Springboot
Scalabilité des applications : 5 pistes pour y parvenir
Scalabilité des applications : les conseils d’AXOPEN, agence de développement web, pour rendre son appli web scalable
Travailler avec des graphistes
Découvrez la planche #34 !




Nous suivre, nous écouter





