
Performances et disponibilités des systèmes distribués
Quelles sont les avantages en termes de performance et de disponibilité offerts par les systèmes distribués ? Exemples de solutions et difficultés de mise en œuvre.
Les systèmes distribués proposent des solutions permettant d’améliorer l’agilité globale du système d’information souhaitée par beaucoup de décideurs, par l’intermédiaire notamment des architectures orientées services (SOA). Ces systèmes permettent aussi de mettre en place des architectures informatiques permettant d’améliorer les performances ainsi que la disponibilité des systèmes informatiques.
Cette étude s’attachera à aborder uniquement l’aspect performances et disponibilité des systèmes distribués par l’intermédiaire de l’analyse des architectures sous-jacentes.
Nous verrons ainsi les avantages de ce type de système mais aussi les difficultés rencontrées lors de leur mise en œuvre.
Analyse des performances des systèmes distribués
Dans la pratique, l’ensemble des composants constituant un système distribué peuvent être déployé sur un serveur physique unique pour des raisons de coût, réparti sur autant de serveur que de composant et même dans certains cas un composant peut être redondé sur plusieurs serveurs pour permettre la tolérance aux pannes (fail over) et/ou la répartition de charge (load balancing). Ces trois scénarios sont illustrés ci-dessous.
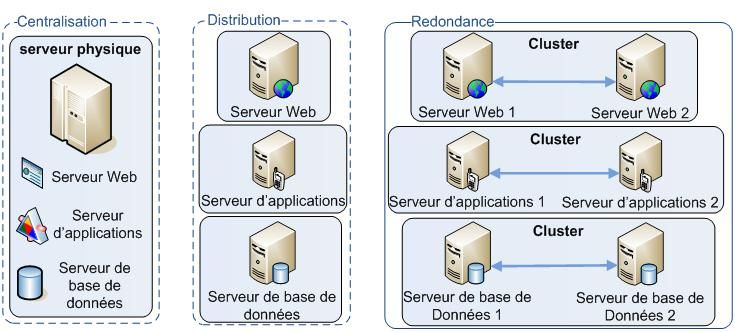
Exemples d’implémentation physique d’un système distribué
Le travail des architectes informatiques consiste alors à proposer une architecture physique et logique au meilleur coût en fonction des contraintes et exigences du système concerné (temps de réponse, délai de reprise sur erreur, taux de disponibilité, volumétrie attendu, nombres d’utilisateurs simultanés…). Cette phase est communément appelée phase de sizing.
__
Les systèmes distribués disposant in fine d’une couche middleware pour assurer la communication entre les différents composants, des solutions fonctionnant sur les différentes couches (physique, logique et applicative) permettent d’augmenter plus facilement la performance globale de ces systèmes.
Le simple fait de répartir l’ensemble des composants d’un système distribué (serveur d’application, serveur de base de données, courtier de messagerie…) sur plusieurs serveurs physiques permet déjà à ce type de système d’offrir de meilleures performances que les systèmes centralisés (mainframes) où tous les composants sont centralisés sur un seul et même serveur physique.
##Capacité à répartir la charge (Load Balancing) Afin d’augmenter la capacité de traitement d’un système distribué il est souvent moins couteux de multiplier le nombre de serveur physique plutôt que d’augmenter la capacité de traitement de ceux-ci.
En effet, l’évolution du coût d’un serveur informatique en fonction de l’évolution de sa capacité de traitement répond à une fonction de type exponentielle.
Plusieurs solutions agissant au niveau physique ou logique permettent de gérer la répartition de charge entre différents serveurs.
C’est le cas notamment de la solution NLB de Microsoft™ présentée dans le chapitre suivant.
Exemple d’une solution de répartition de charges :
Le service NLB (Network Load Balacing) proposé par Microsoft™ depuis Windows 2000 Advanced Server™ ou Windows 2000 Datacenter™ permet de répartir les requêtes des utilisateurs entre plusieurs serveurs, et permet une tolérance de pannes dans la messure ou lorsqu’un serveur ne répond plus, les autres serveurs NLB peuvent prendre sa place.
La solution NLB de Microsoft permet de faire cohabiter jusqu’à 32 serveurs en cluster.
Les serveurs NLB disposent alors en plus de l’adresse IP qui permet de les différencier sur le réseau, d’une adresse IP virtuelle, commune à tous les serveurs.
Le principal avantage de la solution NLB est sa flexibilité, en effet, si nous avons par exemple 3 serveurs en NLB et que la charge devient importante pour ces 3 serveurs, il est possible d’en ajouter un quatrième, qui s’il est déjà pré configuré sera directement opérationnel dès sa mise en place sur le réseau.
Par contre, cette solution ne gère pas la synchronisation des données entre les différents systèmes (cache applicatif, variables de session Web, contenu d’une base de données…). Cette synchronisation peut être assurée uniquement par des solutions applicatives fortement liées au type de composant que l’on souhaite synchroniser.
Haute scalabilité des systèmes distribués
Pour certains composants d’un système distribué la montée en charge est réalisée uniquement par pic. Le composant connaitra un ou plusieurs pics d’activité dans une journée, c’est typiquement le cas pour un composant prenant en charge l’authentification des utilisateurs et le rapatriement des informations de session, ce composant sera sollicité très fortement en début de journée pour l’ouverture des sessions et en fin de journée pour la fermeture (cf. illustration ci-dessous).
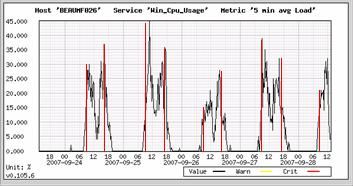
Pour répondre à ces phases de sollicitations importantes la majorité des entreprises sont contraintes à redonder le composant en question sur plusieurs machines physique grâce aux mécanismes de répartition de charge vu précédemment.
Seulement il s’avère qu’avec une répartition de charge classique comme celle vue précédemment le partage des ressources entre les différents composants reste statique. On défini pour chaque composant le nombre d’instances que l’on souhaite créer en fonction de la capacité de traitement cible de ce composant. Or dans notre cas, où le composant est sollicité uniquement par pic d’activité, ce composant va consommer des ressources inutilement lorsqu’il ne sera que très faiblement sollicité.
__
Pour permettre de répondre à cette problématique de nouvelles solutions permettant l’instanciation et la destruction en temps réel d’un composant logiciel ont vues le jour.
C’est le cas notamment de la solution TIBCO ActiveMatrix™ présentée dans le chapitre suivant.
Exemple de solution de haute scalabilité
La solution TIBCO ActiveMatrix™ Service Grid est une plateforme de virtualisation de services permettant d’améliorer le temps de réponse et la capacité d’adaptation d’un système distribué en prenant en charge l’instanciation en temps réel de nouveaux services et processus au sein d’un cluster de serveurs et ceci de manière transparente vis-à-vis des utilisateurs.
Cette solution fonctionne en définissant pour chaque service ou processus hébergé par la plateforme un seuil d’occupation pour lequel il est nécessaire de créer de nouvelles instances permettant d’augmenter la capacité de traitement pour ce service ainsi qu’un deuxième seuil où le système va détruire les instances supplémentaire de ce service qu’il a créé pour répondre au pic d’activité.
L’entreprise n’a plus qu’à gérer une capacité de traitement globale pour l’ensemble de ces services et processus hébergés sur ce type de plateforme.
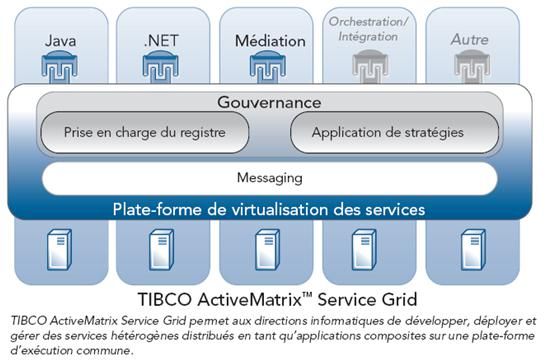
Solution de virtualisation des services TIBCO ActiveMatrix™
Tolérance aux pannes des systèmes distribués (Fail Over)
Les systèmes distribués étant constitués d’un ensemble de composants réparties sur plusieurs machines physiques, ces composants comportent in-fine une couche de communication (middleware) permettant d’assurer la liaison entre les autres composants.
Cette prédisposition à la communication inter-composant permet aux systèmes distribués d’implémenter plus facilement des solutions permettant d’augmenter leur disponibilité. Il s’agit en l’occurrence de solutions permettant de redonder un composant logiciel sur plusieurs serveurs physiques afin de permettre à un deuxième serveur de reprendre la main sur le premier en cas de défaillance de celui-ci.
La majorité de ces solutions imposent tout de même une certaine latence dans la reprise en charge des requêtes d’un serveur défectueux par un serveur en bonne état. De plus, les requêtes envoyées au serveur au moment du plantage ou pendant ce temps de latence ne seront pas traitées par le système. On constate tout de même que quelques solutions adaptées au transport de message proposent des mécanismes de tolérance aux pannes permettant d’assurer aucune perte de requête tout en réduisant la fortement le temps de latence lors du basculement. La solution CAA™ (Continuous Availability Architecture) de Progress Software™ présentée ci-dessous fait partie de ce type de solution.
Exemple d’une solution de tolérance aux pannes :
Progress Software™ commercialise la solution de type bus d’entreprise (Entreprise Service Bus) Sonic ESB™ basée sur l’utilisation d’un serveur de messagerie JMSJava Messaging Service nommé Sonic MQ™.
Dans ce type de solution d’intégration d’application orientée messagerie (Message Oriented Middleware) le serveur de messagerie est au cœur du système, il permet de réaliser l’asynchronisme entre l’émetteur et le récepteur d’un message. Par conséquent, toute indisponibilité de ce serveur de messagerie serait très néfaste sur le fonctionnement du système informatique de l’entreprise concernée.
Pour couvrir ce risque, Progress Software propose une solution de cluster applicatif JMS de type actif/actif ou actif/passif commercialisée sous le nom de CAA™ (Continuous Availability Architecture). __
__
Le serveur JMS est redondé soit en actif/actif, dans ce cas les deux serveurs se répartissent la charge grâce à un répartiteur (load balancing) ou en actif/passif où un seul serveur est actif à un instant donné le second serveur n’ayant pour rôle que d’assurer le relais en cas de panne du premier. Cette solution réplique les données sur chaque nœud et gère automatiquement les arrêts et relance de chaque moteur de messagerie. La bascule d’un nœud vers l’autre est totalement transparente vis-à-vis des clients JMS.
En fonctionnement nominal, pour un cluster actif/actif chaque serveur physique contient deux courtiers de messagerie (broker JMS). Ainsi le serveur n°1 contient le courtier actif n°1 ainsi que le courtier passif de secours n°2, quand au deuxième serveur physique il contient le courtier actif n°2 ainsi que le courtier passif de secours n°1.
Chaque message reçu par le courtier actif n°1 ou 2 est répliqué automatique par le système à sa version passive présente sur un serveur physique différent (cf. illustration ci-dessous).
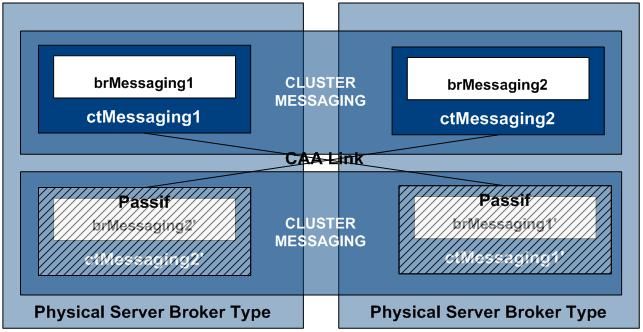
Solution en fonctionnement nominal
Ainsi lors d’une panne de l’un des deux serveurs physique, le courtier passif présent sur le deuxième serveur est capable d’assurer la continuité de service sans perte de message et de manière transparente vis-à-vis des utilisateurs (cf. illustration ci-dessous).
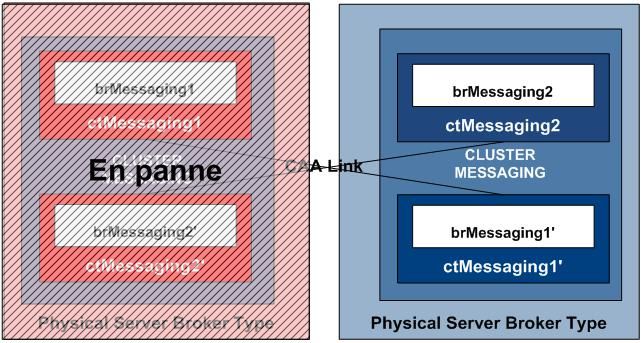
Les difficultés de mise en œuvre
La mise en place de systèmes distribués engendre un certains nombre de difficultés lors de la mise en œuvre, en voici une liste non exhaustive :
• Gestion de l’hétérogénéité
o Horloge globale (synchronisation des horloges)
o Cohérence des données (cache applicatif, base de données, variables de session…)
• Gestion des composants (gouvernance)
• Fonctionnement en mode dégradé
• Disponibilité et détection d’arrêts
• Gestion de la séquentialité
Gestion de l’hétérogénéité : Lors de la mise en place d’un système distribué il est nécessaire que l’ensemble des composants travaillent avec des données cohérentes.
Cette cohérence des données est d’autant plus problématique lorsque l’on commence à redonder certains composants pour augmenter la capacité de traitement et/ou la disponibilité du système. En effet, les données comme le cache applicatif, le contenu d’une base de données ou bien les variables de session des utilisateurs Web doivent être synchronisées entre les différentes instances d’un composant afin d’assurer une cohérence dans les traitements réalisés.
Gestion des composants : Un système distribué étant composé d’un ensemble de composants logiciels répartis sur plusieurs serveurs physique il est nécessaire pour assurer la maintenance corrective et évolutive du système de dresser une cartographie complète de ce système.
Les composants pouvant être utilisés pour de nouveaux besoins en suivant le fameux principe de mutualisation des services prôné par l’architecture SOA, il s’avère alors parfois difficile de prévoir les impacts au niveau des différents systèmes à la suite d’un changement sur l’un des composants.
Disponibilité et détection d’arrêts : Dans un système distribué l’indisponibilité d’un seul composant du système (serveur Web, base de données…) peut rendre indisponible le système complet. On mesure alors la disponibilité de ce type de système à celle de son maillon le plus faible.
Pour couvrir ce risque il est nécessaire de mettre en place en amont une architecture physique permettant d’assurer la disponibilité cible pour tous les composants. Une fois que cette architecture est en production, des opérateurs doivent à l’aide de logiciels s’assurer de la détection au plus tôt d’une défaillance de l’un des composants de l’architecture.
Gestion de la séquentialité : La mise en place d’un cluster de type actif / actif provoque la création de deux points d’entrées au système. Dans le cas d’un système distribué d’échange de données par exemple, Il est alors possible que deux modifications successives du même objet soient dirigées vers deux nœuds différents du cluster, ce qui dans l’absolu peut aboutir à une situation où le message le plus récent est diffusé en premier vers l’application destinatrice.
Si aucune gestion de la séquentialité des messages n’est gérée, le message le plus ancien viendra écraser dans les applications destinatrices le message le plus récent.
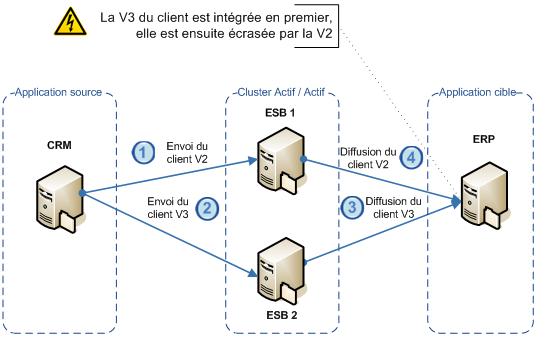
Conclusions
Les systèmes distribués offrent un certains nombre de moyens permettant d’augmenter la performance globale du système et son niveau de disponibilité.
Cependant le choix du niveau de distribution ainsi que du niveau de redondance des composants permettant de déterminer la performance et le niveau de disponibilité global du système reste à la charge de l’entreprise qui met en place ce type de système.
Ce choix doit être réalisé en comparant les contraintes d’exploitation métier et le budget alloué à la mise en place du système. La recherche de la performance sans réelle contrainte métier n’a pas de sens.
Un système distribué permet alors d’atteindre des niveaux de performance et de disponibilité importants plus facilement et à « moindre coût » grâce à l’utilisation de plusieurs serveurs en comparaison avec les systèmes centralisés se basant sur l’utilisation d’un gros serveur unique ayant une capacité de traitement supérieure.
L'équipe AXOPEN
Nos podcasts en lien


Pour aller plus loin
Tuto : enregistrer des scénarios pour ses tirs de performance avec JMeter
On vous explique pas à pas les étapes dans JMeter pour enregistrer un scénario, définir les variables, configurer les threads et les loops dans JMeter. Le but : lancer les tirs de performance !
Mauvais rêve
Découvrez la planche #7 !
Projets persos, veille technologique et motivation : rester passionné quand on est développeur
Chez AXOPEN, on ne chôme pas en août, mais on en profite pour lever un peu le nez du code, prendre du recul… et aborder des sujets qu'on laisse parfois de côté quand le quotidien technique tourne à plein régime.




Nous suivre, nous écouter




