
RAG : comment ça marche techniquement ?
Un RAG (Retrieval Augmented Generation) est un système utilisé dans les entreprises pour améliorer la gestion documentaire, et notamment, faciliter la recherche dans de grosses volumétries de documents. Si vous avez déjà testé d’utiliser l’IA avec les LLM traditionnels pour ce sujet, vous avez sûrement rencontré des problématiques importantes liées au manque de contexte ou de connaissances basé sur les documents (dû à la limite de tokens d’entrée). C’est là où le RAG joue sa carte ! Un RAG a pour but d’alimenter la base de connaissances de votre IA avec vos documents. Et comme, elle se base sur vos données pour répondre aux questions (documents internes, données confidentielles, etc), les réponses sont plus pertinentes ! Dans cet article, nous plongeons au coeur du fonctionnement d’un RAG pour vous expliquer les rouages du système. Let’s go !

Le RAG, comment ça fonctionne ? 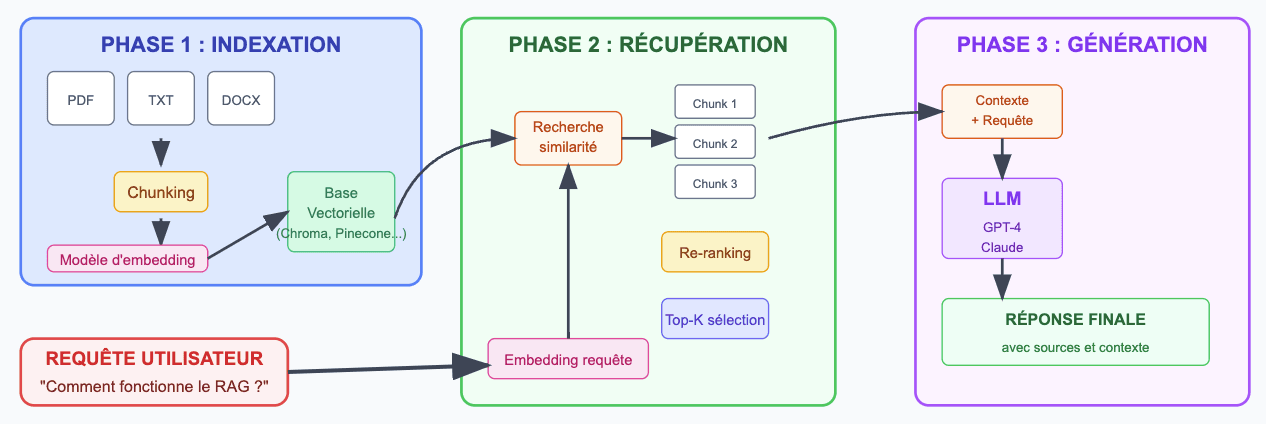
Le système RAG fonctionne en 3 phases distinctes :
Phase 1 - Indexation : Vos documents sont découpés en chunks* pertinents selon leur structure (chapitres, sections), puis transformés en vecteurs numériques et stockés dans une base vectorielle.
Phase 2 - Récupération : Votre requête en langage naturel est convertie en vecteur, puis le système recherche les chunks les plus similaires sémantiquement et sélectionne les K meilleurs scores.
Phase 3 - Génération : Le LLM reçoit votre question originale enrichie du contexte pertinent récupéré pour produire une réponse factuelle basée sur vos données spécifiques.
Qu’est-ce qu’un chunk ?
Un chunk* dans un RAG, c'est comme une fiche de révision ! Vous prenez un gros document (un livre, un manuel) et vous le découpez en petites fiches qui contiennent chacune une idée ou un concept complet. Ainsi, quand vous posez une question, le système va chercher les bonnes fiches pour vous répondre !
Dans un RAG, un chunk est un segment de texte de taille optimisée (généralement 200-1000 tokens) qui représente une unité sémantique cohérente du document source.
Processus de chunking :
- Segmentation : Le document est divisé selon des critères logiques
- Vectorisation : Chaque chunk est transformé en embedding vectoriel via un modèle d'encodage
- Indexation : Les vectors sont stockés dans une base vectorielle
Stratégies de chunking courantes :
- Fixe : Taille constante (ex: 500 tokens avec overlap de 50)
- Sémantique : Basé sur la structure du document (paragraphes, sections)
- Récursif : Découpage hiérarchique avec préservation du contexte
1 - Phase d'indexation : préparer les connaissances 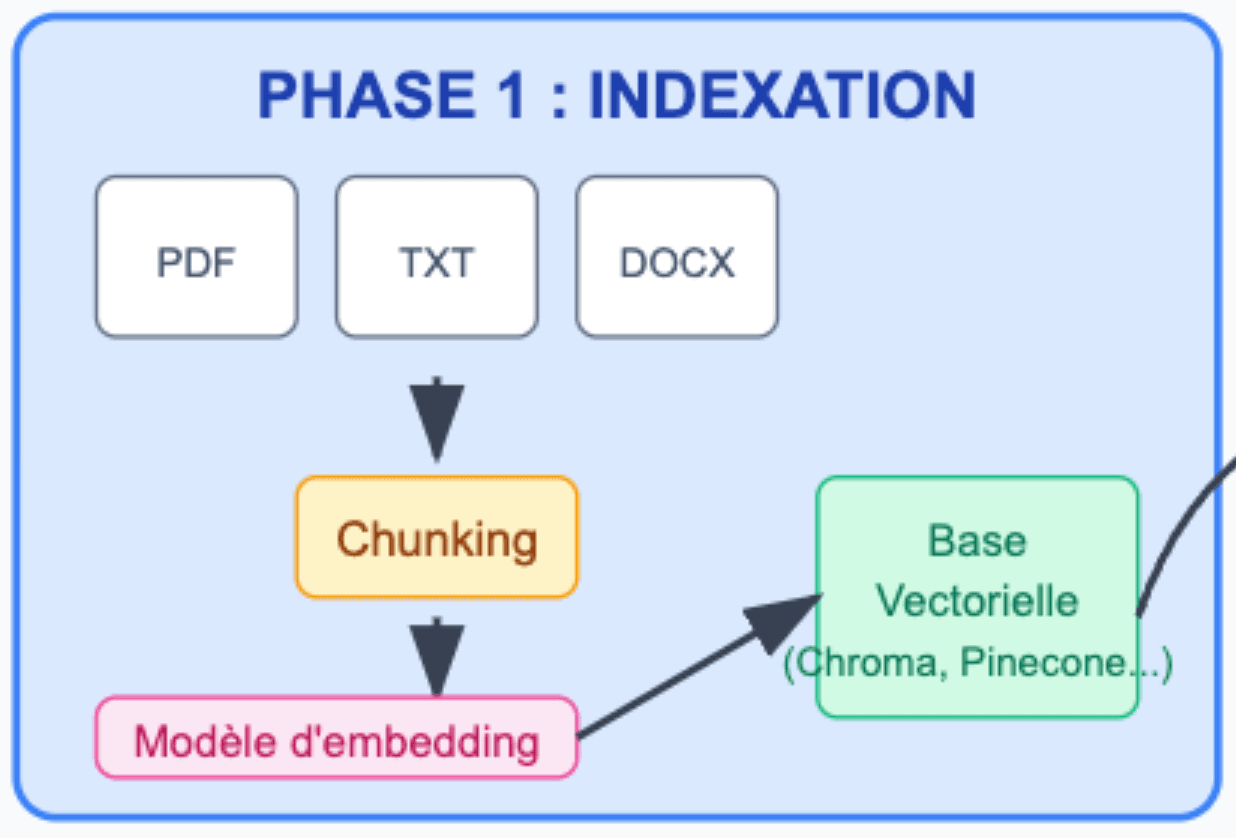
La phase d’indexation de vos documents est vraiment primordiale car elle permet de bien préparer les connaissances pour pouvoir ensuite bien les utiliser.
Concrètement, c’est la base du bon fonctionnement de votre RAG ! L’objectif de cette première phase est d’ingérer les documents, et de les découper en chunks. Pour rappel, un chunk est un morceau de votre document découpé qui sera utile lors de la phase 2 de récupération pour retrouver des informations.
Attention, si votre document est mal découpé et que vos chunks n’ont aucun sens, alors, lors de la phase suivante (récupération), vous ne trouverez pas les informations nécessaires pour votre requête. C’est pour ça qu’il est important de vérifier que vos documents aient des chunks découpés par chapitre ou par section selon vos types de documents.
Souvent en entreprise, nous avons des documents avec des structures bien spécifiques ! Par exemple, dans une ESN, nous avons des documents nommés des DET (documents d’exploitation techniques). Pour ces documents, nous exécutons un pattern de découpage de chunks spécifiques pour que cela corresponde à la structure du type de document pour que nos chunks soient le plus pertinent possible.
Exemple :
Ici, nous avons utilisé une technique d’optimisation de chunking, qui consiste à créer des questions correspondantes aux chunks. Voici un exemple de résultats :

On peux voir que la question cible correctement la contexte de notre tableau et que, si nous questionnons la stack de notre application, le chunk sera bien récupéré grâce à la question.
Une fois que notre découpage en chunks est réalisé, nous stockons les chunks dans une base vectorielle afin de pouvoir effectuer des recherches “vectorielles” et ainsi, avoir le maximum de matching possibles liés à la future requête !
2 - Phase de récupération : trouver l'information pertinente 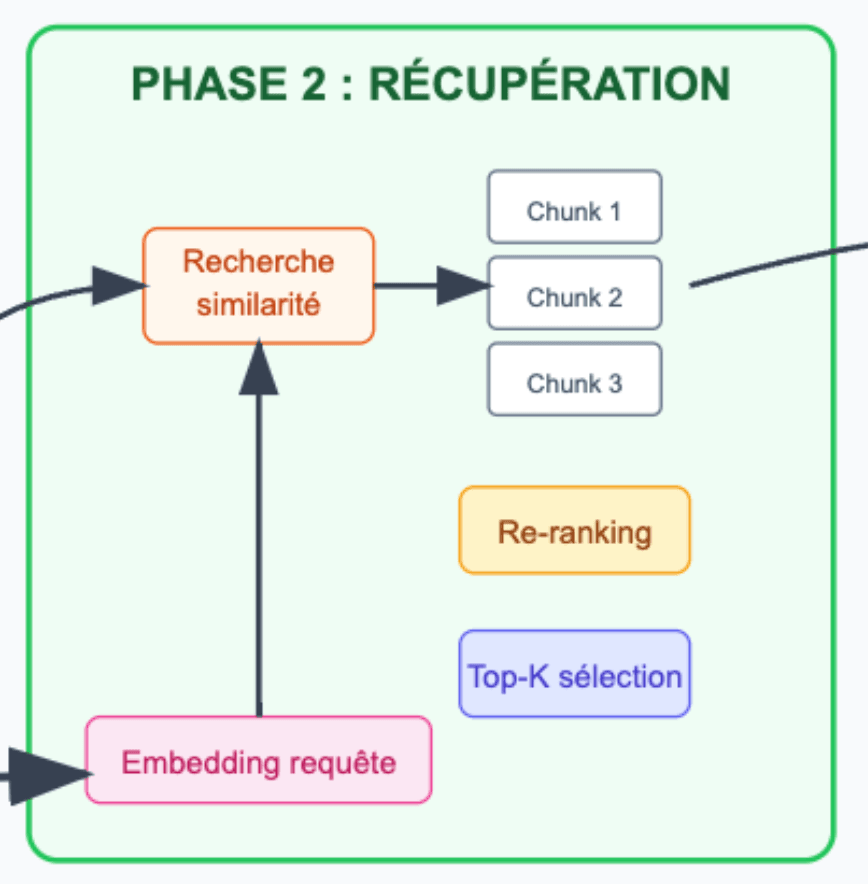
Deuxième étape : la récupération ! Ici, cette phase a pour but de transformer votre requête dite “naturelle” en vecteur numérique (comme sur le schéma “Comment fonctionne le RAG ?” ).
Ce vecteur permet ensuite de rechercher dans la base vectorielle les chunks les plus pertinents en lien avec votre question, en calculant la similarité sémantique.
Pour finir, nous récupérons les K meilleurs chunks ayant obtenu les meilleurs scores afin d’alimenter la dernière phase, dite de “Génération”.
3 - Phase de génération : produire la réponse 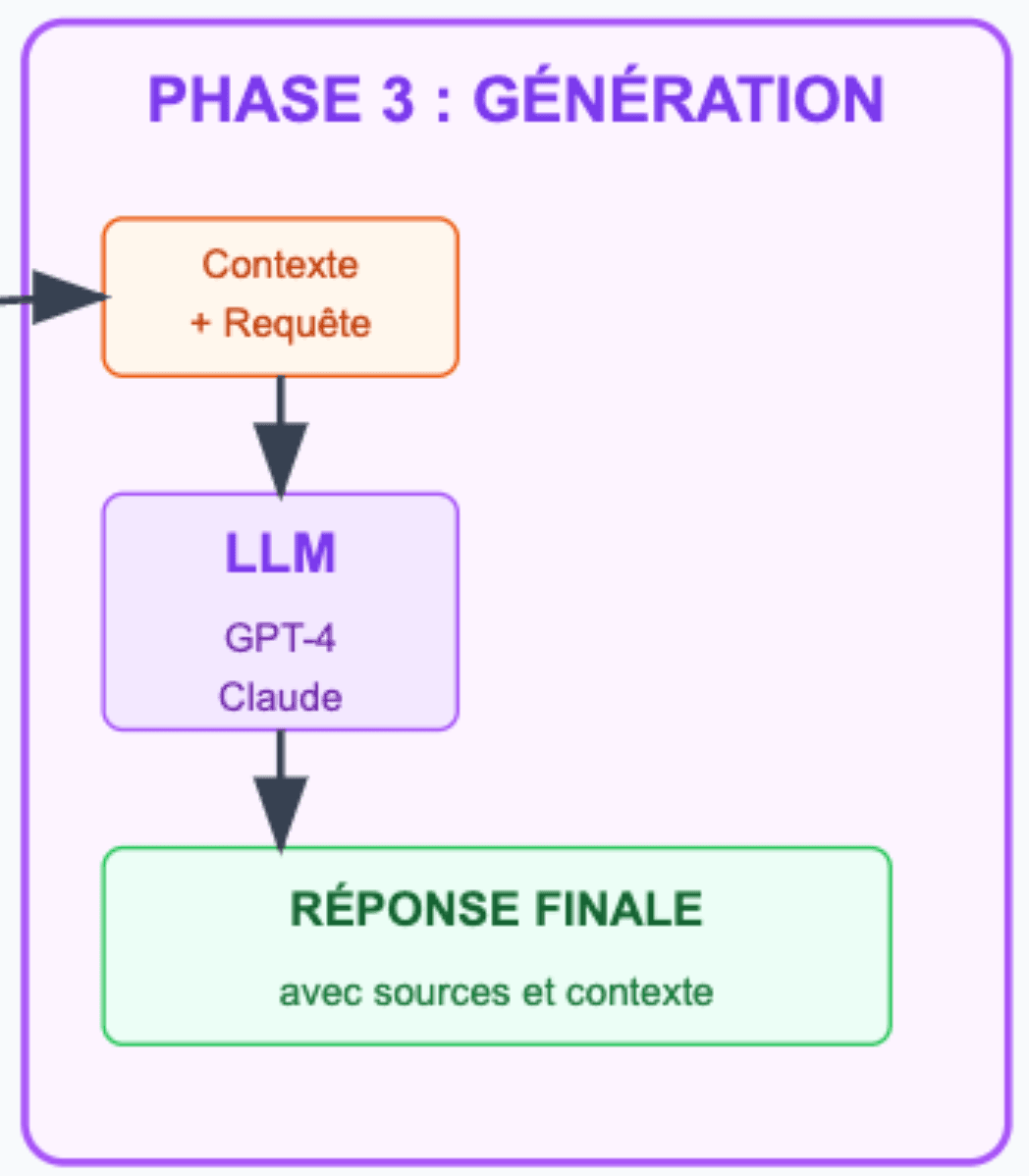
La dernière étape de génération combine votre requête originale avec les chunks de la phase de récupération qui ont été présélectionnés pour construire un prompt enrichi.
Le LLM reçoit donc à la fois votre question et le contexte spécifique extrait de vos documents. Cette approche permet de produire une réponse qui conserve la qualité de génération d’un LLM classique, tout en se basant sur vos données spécifiques !
RAG : les défis à surmonter
Comme nous avons pu le constater précédemment, il y a 2 grands défis qui se présentent sur notre chemin !
Le chunking optimal en fonction des types de contenu
Selon les solutions que vous choisirez pour faire votre RAG, vous aurez des algorithme de chunking déjà prédéfinis. Certains seront bien adaptés à certains types de documents mais… ce ne sera probablement pas le cas de tous ! Alors, dès lors que vous observerez des soucis de résultat, on vous conseille de faire vos propre algo de chunking pour qu’il soit le plus optimal possible selon vos documents.
La gestion des informations contradictoires
Un autre soucis (et non des moindres) que vous pouvez rencontrer est la gestion des informations contradictoires. Dans différents cas, nous pouvons avoir plusieurs documents pour la même source.
Exemple 1 :
- Document A de 2022 : mon API supporte jusqu’à 1000 requêtes/minute.
- Document B en 2025 : mon API supporte jusqu’à 2000 requêtes/minute.
Votre LLM va recevoir ces informations sans temporalité. Alors comment va-t-il choisir les bonnes données à récupérer dans les chunks ?
Exemple 2 :
- Document Marketing : “Notre solution est plus rapide de 50%”
- Document Technique : “Performance variable selon la configuration”
Encore une fois, quelle donnée doit être priorisée par votre LLM alors qu’il n’a pas d’information ?
Si vous êtes dans ces cas et voulez aller plus loin sur le sujet pour résoudre ce type de problématiques, je vous renvoie à notre article sur l’optimisation des RAG.
Points clés à retenir dans le fonctionnement d’un RAG
La RAG représente une révolution dans l’utilisation de vos données d’entreprise, permettant de dépasser les limites fondamentales de contexte et de connaissances figées. Comme nous l'avons vu, sa force réside dans sa simplicité conceptuelle : indexer, récupérer, générer.
Les points clés à retenir :
- L'indexation est critique : un mauvais chunking compromet tout le système
- La récupération sémantique offre une précision bien supérieure aux recherches traditionnelles
- La génération enrichie combine le meilleur des deux mondes : la fluidité des LLM et la factualité de vos données
Cependant, le RAG n'est pas une solution miracle. Les défis que nous avons évoqués - chunking optimal, gestion des contradictions, nécessitent une approche méthodique et des optimisations spécifiques à votre contexte métier. Si vous avez besoin d’aide pour la mise en place de votre RAG d’ailleurs, n’hésitez pas à nous contacter directement.
Nos podcasts en lien


Pour aller plus loin
Les requêtes avec Hibernate 4
Tuto : comment faire des requêtes avec Hibernate 4
Qui se cache derrière le blog AXOPEN ?
Quelques années après avoir créé ce blog, nous nous sommes rendu compte d’une chose : nous ne nous sommes jamais présentés ! Grossière erreur de notre part… Cependant, « vaut mieux tard que jamais », alors on fait un petit rectificatif pour tenter de se r
JasperSoft Studio – Masquer une colonne proprement
JasperReports permet de définir l’affichage conditionnel d’un certain nombre d’éléments afin de les afficher ou non. Néanmoins, dans le cas où le document est affiché sous forme de plusieurs colonnes (ex : juxtaposition de sous-rapport),




Nous suivre, nous écouter




