
Expertise Apache Kafka
Un système d'information en constante expansion, avec un nombre croissant d'applications, voit sa complexité augmenter, rendant la communication entre ses différentes applications un véritable défi. Pour surmonter ce problème, diverses solutions existent, telles que les agents de messages. Parmi eux, Apache Kafka est probablement celui qui se démarque le plus.
Pourquoi nous faire confiance
AXOPEN est spécialisé dans les développements de projets informatiques métiers, techniques et complexes.
à propos de l'auteur


Apache Kafka, qu'est ce que c'est ?
Apache Kafka est un agent de message. Il s'agit d'une application ou d'un service qui a pour but de transmettre une information d'un point A à un point B. Le but est de pouvoir déléguer toute transmission d'informations à l'agent de message, qui va être chargé de valider, stocker, et délivrer l'information aux différentes applications d'un SILe SI désigne le système d'informations d'une organisation..
Cela permet, lorsqu'on a un SI complexe, avec un grand nombre d'applications, de centraliser ce processus, afin de faciliter le découplage entre les applications.
Attention à ne pas confondre les agents de messages et les ESB, comme par exemple Apache ServiceMix. Les ESB sont des outils plus lourds, qui permettent également de gérer la transmission d'informations, mais vont plus loin en transformant le message pour l'adapter aux services cible.
Les différents types de modèles de distribution des messages
Il existe trois grands systèmes d'agents de messages :
- Modèle orienté "souscription" à l'image d'un websocket, les services s'abonnent à un sujet/topic de l'agent pour recevoir les messages associés.
- Modèle orienté queue/file d'attente, chaque application/entité qui attend un message, va se voir attribuer une queue (file d'attente). Lorsqu'un message arrive au niveau de l'agent, il y a un système de routing et de redirection, qui aura été paramétré en amont, au niveau de l'agent, pour les transmettre à une ou plusieurs queues, donc une ou plusieurs applications.
- Modèle orienté log/journal : tous les messages reçus par l'agent sont écrits, puis stockés et affichés. Lorsque les différentes applications vont vouloir lire ces messages, il leur suffit de parcourir ces fichiers de log, à l'aide d'un offset, qui est généralement maintenu et stocké par l'agent. L'avantage de ce modèle est que l'ordre des messages est forcément respecté.
C'est dans cette troisième catégorie que se situe Apache Kafka, il s'agit d'un modèle orienté log/journal, permettant de stocker les messages reçus.
Les avantages d'Apache Kafka
Le scaling
Contrairement à un ESB, il n'y a pas le feu au SI lorsqu'un agent de message cesse de fonctionner. En effet, un agent de message peut contourner ce problème grâce à la scalabilité horizontale. Il est possible de mettre en place plusieurs agents de messages, interconnectés entre eux, formant ainsi un "cluster". Le cluster est réparti sur plusieurs serveurs pour toujours avoir une issue de secours s'il l'un d'entre eux vient à tomber en panne.
Un haut débit
Kafka est capable de délivrer des messages à haut débit, à l'aide d'un cluster de machines, et ce, avec des temps de latence allant jusqu'à 2ms.
Un agent de message évolutif
Il est tout à fait possible de faire évoluer son cluster en ajoutant plusieurs nœuds. Il s'agit d'autres applications Apache Kafka, qui vont s'interconnecter aux solutions existantes et ajouter plus de puissance au système.
Haute disponibilité
Il est possible d'étendre efficacement les clusters sur des zones de disponibilité ou de connecter des clusters distincts à travers différentes régions géographiques.
Stockage permanent
Kafka permet de stocker les flux de données en toute sécurité dans un cluster distribué, durable et tolérant aux pannes.
Comment se forme un cluster ?
Le fonctionnement des clusters avec Kafka
Depuis début 2023, Apache a décidé de se séparer petit à petit de ZooKeeper (l'ancienne solution permettant de gérer les Clusters et ses Métadatas).
Désormais, les Brokers, les Partitions, les Réplicas, les métadonnées, etc., sont gérés par Kafka directement. On appelle ça le mode "KRaft".
Plusieurs méthodes ont été développées pour migrer de ZooKeeper à Kafka.
Comment fonctionnent les Topics Kafka ?
Chaque message reçu est classé dans un "Topic", en fonction de sa nature. Dans un cluster, les Topics peuvent être répartis en plusieurs partitions, eux même répartis dans plusieurs serveurs. Cela permet d'éviter le cas, où, si un seul Topic est sollicité, un seul serveur travaille pour les autres.
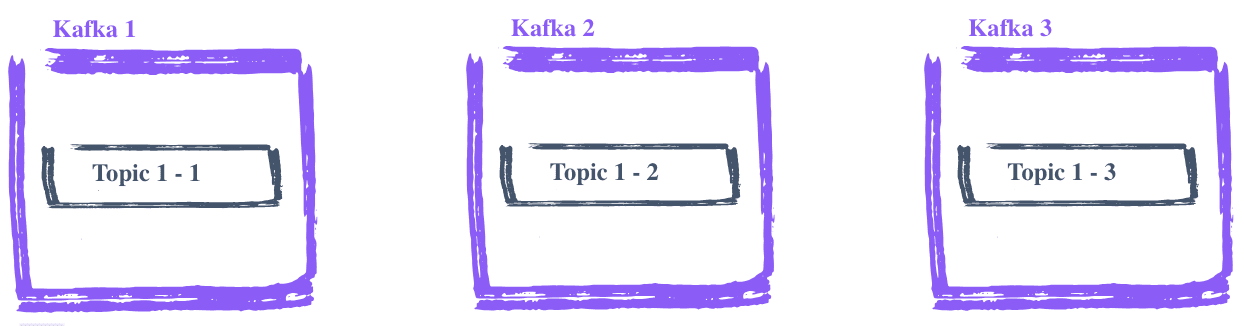
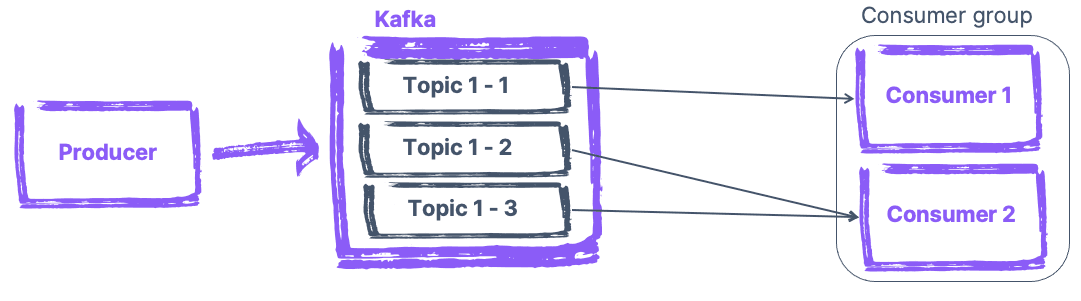
Répartir la charge de lecture des Consumers Kafka
Il se peut que parfois, une quantité énorme de messages soit traitée par des "Consumers", à savoir les applications qui lisent les messages. Dans ce cas, il est possible de créer des "Consumer Group", permettant à ces Consumers de se répartir la lecture des messages, en assignant une ou plusieurs partitions d'un même Topic aux différents Consumers d'un groupe, pour éviter d'avoir à lire deux fois le même message. Cela permet d'avoir un traitement plus efficace des messages, car plusieurs Consumers lisent les différents messages d'un Topic.
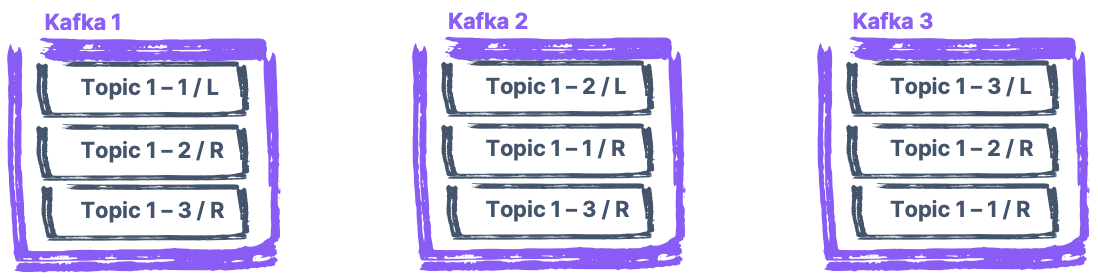
Préserver ses données : les replicas Kafkas
Pour assurer la disponibilité d'une partition, même en cas de défaillance d'un nœud Kafka, il est possible de créer des copies de ses journaux. Ces copies, dites "replicas" en anglais, sont réparties dans les différents serveurs. Une seule version de ces copies est dite "Leader", et communique avec les Producers et les Consumers. Si le serveur sur lequel le leader est installé tombe en panne, une des autres copies située sur un des autres serveurs reprend le rôle de leader. Ainsi, même en cas de problème majeur sur l'un des serveurs, l'activité liée à l'agent Kafka continue de fonctionner sans perte de données.
À noter qu'il est fortement conseillé de renseigner plusieurs points de connexion à un Cluster.
Le petit plus de Kafka : les Streams
Kafka propose une bibliothèque permettant de traiter et d'analyser les données stockées par l'agent, puis d'écrire le résultat final dans Kafka ou de l'envoyer à un système externe. Cela permet notamment d'effectuer ces opérations en temps réel. À l'instar des flux (streams) en Java, il est possible d'appliquer des filtres, des transformations (map), des jointures (join), des agrégations (aggregate), etc., aux messages reçus.
Apache Kafka - Notre offre
Nous sommes en mesure de vous accompagner dans vos projets d'intégration ou de maintenance de vos systèmes Apache Kafka, mais également dans des missions d'expertise, pour répondre à des problématiques complexes, tels que des audits de code. Pour plus de conseils, n'hésitez pas à contacter nos experts Apache Kafka.
Nos podcasts en lien


Pour aller plus loin
Agent de messages (message brokers) : définition et usages
Qu’est-ce qu’un agent de message ou message broker ? À quoi ça sert ? Quels outils : plutôt Apache Kafka ou Rabbit MQ ? Le point avec des exemples sur cet article !
Talend – Contextualiser (variabiliser) le paramétrage
Dans cet article, nous allons voir comment contextualiser vos projets dans l’ETL Talend. La contextualisation consiste à, d’une part, « variabiliser » l’ensemble des paramètres qui sont utilisés dans les jobs (connexion aux bases de données, chemin vers l
Utiliser les Proof of Work pour régler les problèmes des captchas modernes
Il se peut que vous ayez déjà cherché une solution de captchas pour protéger votre site contre les botters. Il est facile de se perdre dans les différentes solutions existantes, nous proposons aujourd'hui un comparatif des différentes options possibles avant de s'intéresser à l'application des Proof of Work dans ce problème.




Nous suivre, nous écouter





