
Pourquoi utiliser Elasticsearch ? Guide complet pour comprendre son fonctionnement
Dans un monde où la donnée est au cœur de chaque projet informatique, la question n'est plus de savoir si vous devez exploiter les données, mais comment L'un des outils les plus utilisés pour répondre à ce besoin est Elasticsearch, un moteur de recherche et d'analyse distribué, capable de traiter d'énormes volumes de données en quasi temps réel.

Dans chaque entreprise, chaque projet, chaque application, les données sont omniprésentes. Que ce soit pour consulter un catalogue, pour rechercher un document, mettre à jour un profil ou encore remplir un formulaire, l'utilisateur d'une application interagit sans cesse avec une base de données.
Mais toutes les bases de données n'ont pas les mêmes points forts et points faibles. Lorsqu'il s'agit de retrouver rapidement une information précise au milieu de millions de documents, les bases relationnelles classiques peuvent montrer certaines limites.
C'est là qu'intervient Elasticsearch, un moteur de recherche et d'analyse distribué, pensé pour gérer ces problématiques de performance, de pertinence et de scalabilité. Basé sur la bibliothèque Lucene, il offre de solides capacités de recherche et d'exploration.
Qu'est-ce qu'Elasticsearch ?
Contrairement à une base de données relationnelle classique, qui excelle dans les jointures et la cohérence stricte, Elasticsearch se spécialise dans :
- Sa capacité à effectuer des recherches textuelles avancées (tolérance aux fautes, pondération des résultats, recherche approximative) ;
- L'analyse et l'agrégation rapide de données massives ;
- Une architecture distribuée qui permet une montée en charge horizontale.
En pratique, on le retrouve dans :
- Les moteurs de recherche internes (sites e-commerce, catalogues, applications métier) ;
- L'analyse de logs et monitoring (souvent intégré avec Logstash et Kibana dans la stack ELK) ;
- La cybersécurité et la détection d'anomalies.
- Les systèmes de recommandation ou d'exploration de données.
Est-ce qu'Elasticsearch est vraiment pertinent pour tous les projets ?
Avant de nous intéresser à son fonctionnement, penchons nous d'abord sur avantages et les inconvénients d'Elasticsearch, ainsi que sur les cas de figures pertinents pour son utilisation.
Les avantages
- Performance : des recherche en millisecondes, même sur des millions de documents.
- Flexibilité : données semi-structurées, JSON natif, pas besoin d'un schéma rigide.
- Scalabilité : extension facile grâce aux clusters multi-nœuds.
- Écosystème riche : Kibana pour la visualisation, Logstash/Beats pour l'ingestion, connecteurs multiples.
Les limites
- Ressources : Elasticsearch consomme beaucoup de RAM et de CPU.
- Complexité opérationnelle : tuning des index, gestion du cluster… nécessite une certaine expertise pour le déployer à grande échelle.
- Pas une base de données transactionnelle : il ne remplace pas PostgreSQL ou MySQL pour les transactions ACID.
Elasticsearch est un outil puissant qui constitue un bon choix si vous avez besoin de recherches rapides et complexes sur de gros volumes de données, ou d'analyses en temps réel (logs, métriques, événements) mais un mauvais choix si vous cherchez une base relationnelle complète, ou si vos données sont modestes et vos recherches simples (un SQLLangage permettant de communiquer avec une base de données. bien optimisé suffira).
Il ne vient donc pas remplacer un bases de données relationnelle existante (PostgreSQL, MySQLMoteur de gestion de base de données., …) mais plutôt s'ajouter à celle-ci de façon complémentaire.
Le fonctionnement d'Elasticsearch
Pour illustrer le fonctionnement d'Elasticsearch, prenons un exemple simple en JavaLangage de développement très populaire ! avec une classe Livre :
import lombok.Getter;
import lombok.Setter;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Getter
@Setter
public class Livre {
@Field(type = FieldType.Text)
private String title;
@Field(type = FieldType.Text)
private String author;
@Field(type = FieldType.Float)
private Float price;
}
Indexation des documents dans Elasticsearch
La première étape pour permettre la recherche est d'indexer nos documents.
Cela peut se faire "à la volée" lors de la création d'un nouveau livre (POST) :
{
"title": "Elasticsearch par la pratique",
"author": "Antoine Chataignier",
"price": 39.90
}
Ou bien via un script périodique qui réindexe les données depuis votre base relationnelle.
L'indexation consiste à :
- Analyser le texte (tokenisation, normalisation, stemming).
- Construire un index inversé : plutôt que de stocker documents → mots, on stocke mots → documents, ce qui permet une recherche ultra rapide.
Ce qui nous donnerait ici :
titleetauthorsont de typetext→ ils seront tokenisés (découpé en mots).priceest un champ numérique → il n'est pas découpé en mots, mais indexé tel quel pour permettre des recherches par valeur ou des agrégations.
Voici à quoi pourrait ressembler l'index inversé :
| Mot/token | Documents contenant ce mot |
|---|---|
| elasticsearch | [doc 1] |
| par | [doc 1] |
| la | [doc 1] |
| pratique | [doc 1] |
| antoine | [doc 1] |
| chataignier | [doc 1] |
Et après l'enregistrement du nouveau livre suivant :
{
"title": "Pratique manuelle de la pensée",
"author": "Antoine Dupont",
"price": 0
}
Nous pourrions avoir l'index inversé suivant :
| Mot/token | Documents contenant ce mot |
|---|---|
| elasticsearch | [doc 1] |
| par | [doc 1] |
| la | [doc1, doc2] |
| pratique | [doc1, doc2] |
| antoine | [doc1, doc2] |
| chataignier | [doc 1] |
| manuelle | [doc2] |
| de | [doc2] |
| pensée | [doc2] |
| Dupont | [doc2] |
Ce qui rend alors très facile la recherche de livres à partir d'une recherche textuelle.
Recherche dans Elasticsearch
Une fois nos documents (ici des livres) indexés, il est possible de récupérer rapidement une liste d'élements selon certains critères :
{
"query": {
"match": {
"title": "Elasticsearch"
}
}
}
Résultat : tous les livres dont le titre contient "Elasticsearch".
Les requêtes peuvent devenir bien plus complexes, combinant filtres, pondération, exclusions ou recherche sur des champs imbriqués. Voici un exemple de requête légèrement plus compliquée possible :
{
"bool": {
"filter": [
{
"terms": {
"code": ["xxx", "yyy"]
}
}
],
"should": [
{
"query_string": {
"boost": 1.0,
"analyze_wildcard": true,
"default_operator": "or",
"fields": ["title"],
"query": "Elastic OR search"
}
},
{ "term": { "excludeArchive": { "value": true } } },
{
"nested": {
"ignore_unmapped": true,
"path": "author",
"query": {
"bool": {
"should": [
{
"query_string": {
"boost": 1.0,
"analyze_wildcard": true,
"default_operator": "or",
"fields": ["author.name"],
"query": "Axopen"
}
}
]
}
}
}
}
]
}
}
Lors d'une recherche, Elasticsearch interroge chaque shard (sous-division d'un index pour permettre la distribution des données), calcule les scores de pertinence et agrège les résultats pour renvoyer une réponse unique.
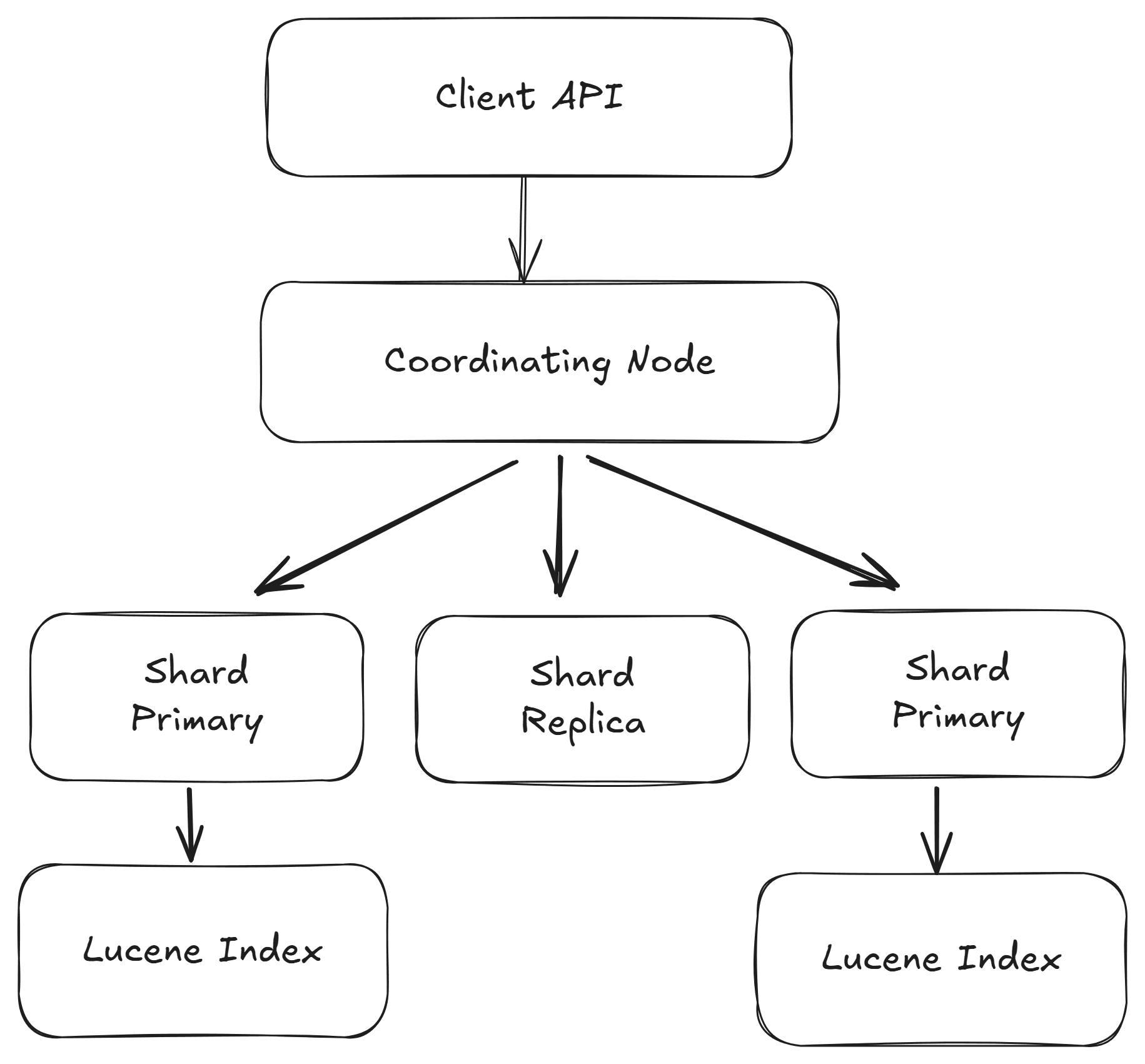
Cette architecture permet non seulement une forte résilience mais offre aussi la possibilité d'une scalabilité horizontale.
Lucene, qu'est-ce que c'est ?
Avant de conclure, il est essentiel de faire un point sur la technologie sous-jacente d'Elasticsearch : Lucene.
Cette librairie Java est le véritable moteur de recherche derrière Elasticsearch. En réalité, chaque shard d'Elasticsearch n'est rien d'autre qu'un index Lucene.
Lucene fournit toutes les briques essentielles pour :
- Construire et maintenir un index inversé.
- Gérer la tokenisation et l'analyse des textes (minuscules, accents, racines de mots, synonymes…).
- Calculer la pertinence des résultats grâce à des algorithmes.
- Effectuer des recherches complexes (recherche booléenne, fuzzy search, phrase search, proximité de mots, etc.).
Mais Lucene reste relativement bas niveau. C'est pourquoi Elasticsearch encapsule Lucene derrière une APIUne API est un programme permettant à deux applications distinctes de communiquer entre elles et d’échanger des données. HTTP/JSON facile à utiliser et gère automatiquement la distribution des index en shards et réplicas, facilitant alors son utilisation.
Elasticsearch : ce qu'il faut retenir
Elasticsearch n'est pas une base de données miracle qui répond à tous les besoins, mais un outil spécialisé, pensé pour exceller dans la recherche et l'analyse à grande échelle. Là où une base relationnelle atteint vite ses limites, Elasticsearch offre rapidité, pertinence et scalabilité.
Elasticsearch n'est pas là pour remplacer vos systèmes existants, mais pour les compléter. Si vous cherchez une base transactionnelle classique, il vaut mieux rester sur du SQL avec une base de données PostgreSQL ou MySQL. Cependant, si vos besoins tournent autour de la recherche avancée et de l'analyse de données, Elasticsearch est probablement un excellent choix qu'il serait probablement pertinent d'expérimenter en complément de votre base de données relationnelle !
Nos podcasts en lien


Pour aller plus loin
Le rôle de l’architecture dans les SI
Quel est le rôle d'un architecte système d'information ? Son apport concret dans les projets de développement d'applications.
Big Data et SOA : Combo Gagnant ?
Est ce que le Big Data le SOA est le combo gagnant ?
Sentry, l'alternative crédible à Firebase et AppInsight ?
Vous êtes arrivé sur cette page peut-être par curiosité ou via une recherche un peu plus spécifique dans le but d'en apprendre davantage sur Sentry ? Excellente nouvelle ! C'est là tout l'objectif de cet article dans lequel nous découvrirons ce qu'est Sentry, son utilité, les fonctionnalités principales qu'il propose, comment l'installer en local sur une machine de développement puis comment l'implémenter dans divers projets. Vous êtes prêt ? C'est parti !




Nous suivre, nous écouter




