
Tuto : construire un serveur web en Rust avec Rocket et Diesel
Découvrez pas à pas comment faire votre premier serveur web en Rust avec Rocket et Diesel !

Rust et le web : mode d'emploi
Rust : c'est quoi ?
Rust est un langage de programmation multiplateforme développé par Mozilla depuis 2006. Il est axé sur la performance, l'efficacité et sa fiabilité.
Il est un choix pertinent lorsque l'on veut faire du web car de nombreux frameworks très complets et viables en production existent.
Le but aujourd'hui est de faire un premier pas dans le web avec Rust en réalisant une petite page web capable d'afficher des données préalablement retrouvées depuis une base de données.
Le projet que nous allons réaliser est disponible dans sa version finale ici. Vous ne pourrez cependant pas le tester avant d’avoir suivi l’étape “Installer le client diesel”.
Quels outils va-t-on utiliser pour ce tuto ?
Rocket : c'est quoi ?
Rocket est un framework web très rapide à prendre en main, très bien documenté et flexible, permettant de réaliser des applis web plus ou moins complexes.
Tera : définition
Tera est un moteur de templates très bien supporté par Rocket. Il nous permettra de créer des pages web dynamiques.
Diesel : qu'est-ce que c'est ?
Diesel est un ORM. Si l'installation de son CLI est assez compliquée sous Windows, il est cependant l'ORM le plus utilisé pour Rust.
À noter que diesel ne supporte pas encore l'asynchrone.
On peut représenter le fonctionnement de notre future appli comme ceci :
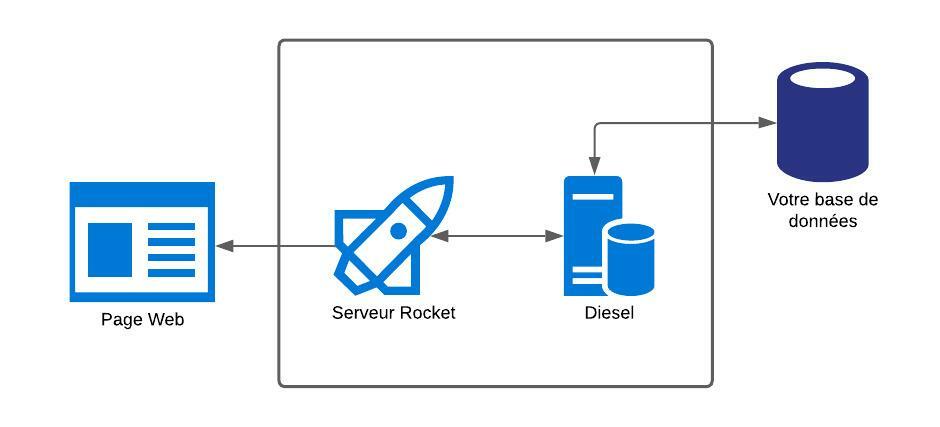
Mise en place de l'environnement
1. Créer un nouveau projet Rust
On part du principe que rust nightly est déjà correctement installé sur votre machine (sinon consultez https://www.rust-lang.org/tools/install + exécution de la commande rustup default nightly).
Pour démarrer un projet en Rust, il suffit d'exécuter la commande cargo init dans un nouveau répertoire.
2. Ajouter les dépendances du projet
Ajoutons des dépendances à notre projet en éditant le fichier cargo.toml comme ceci :
[package]
name = "article_site"
name = "article_site"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
#Rocket
rocket = "0.5.0-rc.2"
#Templating
tera = { version = "1", default-features = true} #moteur de template
rocket_dyn_templates = {version = "0.1.0-rc.2", features = ["tera"]}
#Diesel
diesel = { version = "2.0.0", features = ["mysql"] }
#Ici on choisit mysql, en fonction de votre bdd, vous auriez pu choisir :
#["postgres"] ou ["sqlite"]
#Autres
dotenvy = "0.15" #permet de lire des fichiers d'environnements (.env)
serde = { version = "1.0", features = ["derive"] } #permet de dériver la sérialisation des objets
3. Installer le client Diesel
À la date de cet article, Diesel ne supporte que PostgreSQL, MySQL et SQLite. L’installation du CLI va être un peu laborieuse…
Le client Diesel est l’outil qui nous permettra de configurer Diesel et de mettre en place nos premières migrations.
Avant de l'installer, il va falloir remplir quelques préconditions
Récupérer les librairies statiques
Diesel dépend de librairies statiques compilées pour chaque moteur SQL supporté. Il est possible de n’installer qu’un seul de ces moteurs. Pour ce faire, ne téléchargez alors que la lib du moteur désiré.
Les librairies que nous allons récupérer dans les prochaines parties sont à mettre dans un dossier que vous garderez. Par exemple, un répertoire “diesel_dep” dans “Mes Documents” fera l’affaire.
Les lib que nous allons utiliser peuvent aussi être trouvées (plus facilement) ailleurs sur la toile mais puisque ces sources ne sont pas vérifiées, nous vous déconseillons de procéder ainsi.
MySQL
Les librairies de MySQLMoteur de gestion de base de données. sont disponibles sur le site officiel : https://downloads.mysql.com/archives/c-c/
Il faudra alors télécharger l’archive correspondante à votre système (x64 ou x32). La librairie sera alors disponible à \lib\libmysql.lib. il faudra la renommer en "mysqlclient.lib”
Il faut aussi ajouter dans le répertoire des lib le fichier libmysql.dll, nous en aurons besoin plus tard…
PostgreSQL
Vous trouverez l’archive contenant la librairie à https://www.enterprisedb.com/download-postgresql-binaries.
Une fois celle-ci extraite, l’archive sera récupérable à l’emplacement pgsql\lib\libpq.lib
SQLite
Pour SQLite, c’est une autre histoire. il va falloir compiler vous-même la librairie. Vous aurez alors besoin de 2 ressources, toutes dispo sur https://www.sqlite.org/download.html :
- Les fichiers sources (sqlite-amalgamation-3390400.zip)
- Les binaires (sqlite-dll-win64-x64-3390400.zip à choisir en fonction de votre système x32 ou x64)
Une fois ces deux archives téléchargées, il est nécessaire de les extraire dans le même répertoire pour la suite. Vous devriez alors avoir :
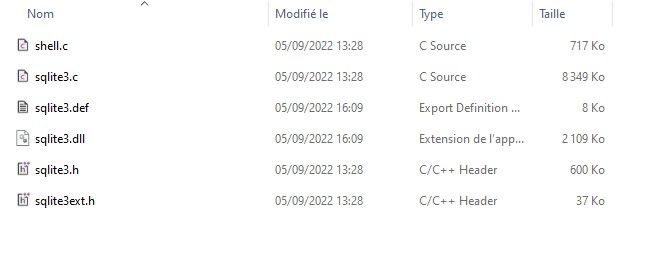
Pour build la lib, il vous faut ouvrir l’invite de commande VS en tapant dans la recherche Windows “Developper Command Prompt for VS” puis vous déplacer là où vous avez extrait les fichiers source avec cd /d chemin/vers/sources et exécuter la commande :
lib /DEF:sqlite3.def /OUT:sqlite3.lib /MACHINE:x64
Alors, “sqlite3.lib” apparaîtra dans le répertoire.
Ajouter une librarie dynamique
Lorsque nous étions allés chercher la librairie statique pour MySQL, vous deviez également copier le fichier libmysql.dll. Cette librairie dynamique est nécessaire au bon fonctionnement de Diesel. Veuillez alors ajouter le répertoire des libs à la variable d'environnement PATH de Windows.
Vous pouvez faire ceci depuis l'outil de Windows ouvert par la commande :
rundll32 sysdm.cpl,EditEnvironmentVariables
Installer le client Diesel (enfin)
Avant de lancer l'installation, il faudra d’abord renseigner quelques variables d’environnement. Celles-ci indiqueront où trouver les librairies statiques précédemment récoltées.
Avec PowerShell on a :
setx PQ_LIB_DIR “chemin/vers/les/libs/statiques”
setx MYSQLCLIENT_LIB_DIR “chemin/vers/les/libs/statiques”
setx SQLITE3_LIB_DIR “chemin/vers/les/libs/statiques”
RÉUSSITE : la valeur spécifiée a été enregistrée. vous indique que la commande s'est bien executée.
Alors, après avoir fermé et relancé votre terminal, vous pourrez lancer l’installation du client avec :
cargo install diesel_cli --all-features
Maintenant, la commande diesel -V devrait retourner quelque chose.
Configurer Diesel
À la racine du projet, lancez les commandes :
setx DATABASE_URL "mysql://user:password@url:port/db_name"
diesel setup
La variable d’environnement “DATABASE_URL” contient l’url de la base de données. Elle sera utilisée par le CLI lors de l'exécution de migration, entre autres.
par exemple,
setx DATABASE_URL "mysql://root:@127.0.0.1:3306/article_base"
diesel setup
Votre première page
Migrations
Pour créer un nouveau fichier de migration, on exécute
diesel migration generate initial_migration
On peut ensuite éditer cette migration. Nous allons créer une table très simple
-- up.sql
CREATE TABLE liste (
id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
libelle VARCHAR(100) NOT NULL
);
INSERT INTO liste (libelle) VALUES
('a'),
('b'),
('c'),
('d'),
('e');
-- down.sql
DROP TABLE liste;
Ensuite exécutons la migration
diesel migration run
Renseigner nos modèles
Ici on en a qu'un, mais sur de plus gros projets, les modèles s'entassent. Il est alors conseillé de les déplacer dans un ou plusieurs fichiers à part.
- Créer un répertoire dans /src appellé models.
- Créer dans models un fichier mod.rs
Vous devriez avoir la structure de fichier suivante :
/src
│ main.rs
│
└───models
mod.rs
Maintenant, il faut renseigner notre table SQL dans le code sous forme de structure :
//models/mod.rs
use diesel::prelude::*;
use serde::Serialize;
#[derive(Queryable)]
#[derive(Serialize)]
pub struct Liste {
pub id: i32,
pub libelle: String,
}
Template (front)
Dans un premier temps, les fichier tera sont rangés dans un répertoire templates dans la racine du projet. Commencez donc par créer ce dossier puis ajoutez y un fichier index.tera.
La syntaxe de tera est semblable à celle de twig, une documentation plutôt complète peut être trouvée ici.
Vous devriez avoir la structure de fichier suivante désormais :
Racine du projet
│ .gitignore
│ Cargo.lock
│ Cargo.toml
│ diesel.toml
│
├───migrations
│ │ .keep
│ │
│ └───<date>_initial_migration
│ down.sql
│ up.sql
│
├───src
│ │ main.rs
│ │ schema.rs
│ │
│ └───models
│ mod.rs
│
│
└───templates
index.tera
Il est possible que /src/schema.rs n’apparaisse pas encore. Pas de soucis à vous faire, il sera auto généré plus tard.
Maintenant, nous allons éditer notre index.tera pour qu'il affiche des données que l'on récupérera dans la prochaine partie.
<body>
<html>
<ul>
{% for list_item in list %}
{# list correspond à un tableau contenant des lignes de la table `Liste` #}
<li>{{ list_item.id }} - <strong>{{list_item.libelle}}</strong></li>
{% endfor %}
</ul>
</html>
</body>
Fichier .env
Les fichiers d'environnements permettent aux serveurs de trouver des valeurs clés. Ces valeurs étant plus facilement modifiables, car toutes regroupées dans un fichier dédié et c'est aussi plus sûr de ne rien avoir écrit en dur dans le code.
Notez que l'on pourrait aussi écrire des variables d'environnements Windows. Mais l'utilisation de fichier d'environnements est préférable car plus propre.
D'ailleurs, cette partie du tuto est facultative car la variable d'env DATABASE_URL a été créée plus tôt.
Si vous voulez faire les choses bien, je vous laisse créer un fichier .env à la racine du projet et y insérer l'url de votre db :
Si vous utilisez GIT, n'oubliez pas d'ajouter le .env au .gitignore
DATABASE_URL=mysql://user:password@url:port/db_name
Mise en place de la route (back)
#[macro_use] extern crate rocket;
extern crate tera;
pub mod models;
pub mod schema;
//imports ~ rocket + templates
use rocket_dyn_templates::{Template, context};
use rocket::response::content;
//diesel
use diesel::mysql::MysqlConnection as SQLConnection;
/*
> en fonction de votre moteur de bdd vous auriez pu mettre :
use diesel::pg::PgConnection as SQLConnection;
use diesel::sqlite::SqliteConnection as SQLConnection;
*/
use diesel::prelude::*;
use dotenvy::dotenv;
//autres
use std::env;
#[get("/")]
fn index() -> content::RawHtml<Template> { //on retourne du HTML, généré par un template
use self::schema::liste::dsl::*; //permet l'utilisation d'alias
let mut c = establish_connection(); //fonction définie plus bas dans le code
let results = liste.load::<models::Liste>(&mut c).expect("Impossible de charger la liste"); //on charge TOUTES les lignes de notre table `liste`
content::RawHtml(Template::render(
"index", //nom du template (index.tera)
context! { list: results }, //on passe en argument à notre template le résultat de notre requête sql
))
}
#[launch]
fn rocket() -> _ {
rocket::build()
.mount("/", routes![index]) //on active notre route
.attach(Template::fairing()) //on ajoute le templating au cycle de vie de rocket
}
pub fn establish_connection() -> SQLConnection {
dotenv().ok(); //charge les variables présente dans le .env dans l'environnement
let database_url = env::var("DATABASE_URL") //on tente de récuperer l'url de la BDD depuis l'environnement
.expect("DATABASE_URL must be set"); //si elle n'existe pas on lève une erreur
SQLConnection::establish(&database_url) //on tente d'établir une connexion avec la BDD
.unwrap_or_else(|_| panic!("Error connecting to {}", database_url)) //on retourne cette connexion (ou une erreur si connexion impossible)
}
Pour conclure
Après avoir lancé le serveur via cargo run, on peut se rendre sur http:// 127.0.0.1:8000 et voir ainsi apparaitre les valeurs que nous avions entrées en base de données.
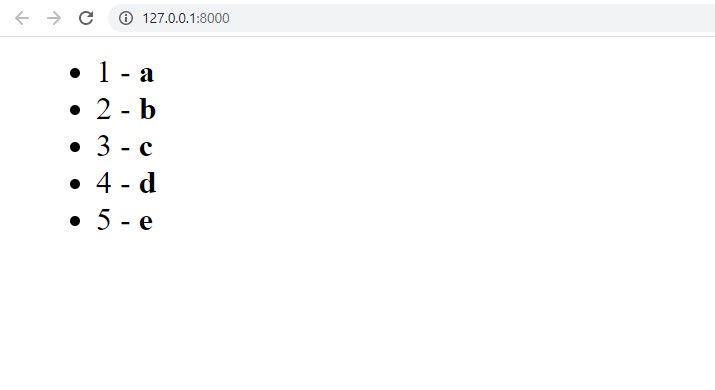
Félicitations !
Un retour, une question ? N'hésitez pas à nous contacter pour en discuter !
Nos podcasts en lien


Pour aller plus loin
Les nativeQuery en Hibernate 4, ou comment lancer une requête écrite « en dur »
Tuto - Les nativeQuery en Hibernate 4, ou comment lancer une requête écrite « en dur »
Kubernetes, c’est quoi et comment ça marche ?
Kubernetes, c’est quoi ? Comment ça marche ? Définition, avantages et inconvénients.
Migration SI legacy : les erreurs à éviter en tant que DSI
D'expérience, il n'y a pas de sujet qui cristallise plus d'angoisse dans une DSI que la migration legacy. Dès qu'on l'évoque, les visages se crispent et le mot "impossible" arrive assez rapidement dans la conversation. Pourtant, derrière cette réputation de monstre intouchable se cache souvent une réalité plus simple qu'on ne le croit !




Nous suivre, nous écouter





