
Spring Batch : Implémentation et présentation du framework Java
Spring Batch c'est quoi ? Spring Batch permet le traitement de gros volumes de données en Java. Comprendre les fonctionnalités et meilleures pratiques.

Spring Batch, c’est quoi ?
Spring BatchC'est un framework Java basé sur Spring qui a pour but de faciliter la création de batch (utilisé pour traiter de grands volumes de data). est un framework Java basé sur Spring qui a pour but de faciliter la création de batch.
Pour rappel, on parle de batch lorsqu’il s’agit d’un traitement sur un gros volume de données.
Spring Batch, pour quels besoins ?
Le but principal de Spring Batch est de fournir un panel d’outils permettant de faciliter le développement de batch.
Grâce à Spring Batch, il est possible de créer des batchs facilement en répondant aux différents problèmes récurrents lors de la création de batch en Java :
- L’intégration du batch dans une architecture utilisant déjà le Framework Spring.
- Une division du code bien définie permettant une maintenabilité facilitée et une logique commune à la création de batch.
- Permettre de traiter un gros volume de données par lots, et alléger les charges des différentes instances sollicitées dans le batch.
Comment implémenter Spring Batch?
Voici un schéma qui représente la relation entre les différentes classes utilisées lors de l’exécution d’un Job. À noter que dans ce framework, lorsque l’on parle de batch on parle plus précisément de Job.
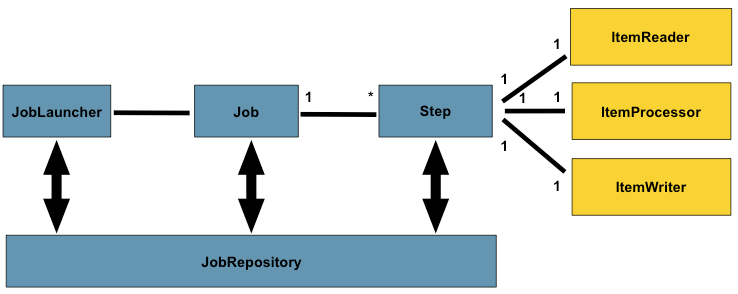
Source : https://docs.spring.io/spring-batch/reference/domain.html
Le JobLauncher
Le JobLauncher permet de lancer un job. Il existe différentes façons de lancer un job, il est possible de le faire de façon synchrone ou bien asynchrone. Le choix de lancer un Job de façon asynchrone est très pertinent pour une application Web car cela va permettre d’effectuer un traitement long via une API REST et de ne pas garder la session HTTP active.
Le JobRepository
Le JobRepository est la classe qui va stocker un grand nombre de données autour du Job. À travers cette classe, il va être possible de récupérer un historique des différents jobs qui ont été lancés avec un grand nombre de données pertinentes. C’est majoritairement grâce à cette sauvegarde de données que l’on peut redémarrer des Jobs ou bien effectuer des pauses dans le traitement.
Le Job
Le Job est la représentation du batch à travers le FrameworkUn framework est un ensemble d'outils permettant de cadrer la façon dont on conçoit une application. Spring Batch. Cette classe va pouvoir définir différentes Step au sein de son exécution avec un ordre précis.
Un exemple de configuration de Job :
/**
* Définit le bean correspondant au job du batch.
*
* @param stepBatch Step qui va être exécuté par le Job.
* @param stepBatchTwo Step qui va être exécuté par le Job.
* @return Job
*/
@Bean(name = "jobBatch")
public Job job(@Qualifier("stepBatch") Step stepBatch,
@Qualifier("stepBatchTwo") Step stepBatchBis) {
return jobBuilderFactory.get("jobBatch")
.start(stepBatch)
.next(stepBatchBis)
.build();
}
Une Step
Une Step va représenter une étape au sein du batch. Si durant le traitement, on souhaite effectuer différentes tâches, cela va se représenter par l’utilisation de différentes Steps. Les Steps sont généralement stockées dans des Beans pour pouvoir y accéder facilement dans différents Job.
Il existe deux types de Step :
-
De type Chunk.
-
De type Tasklet.
Des Steps orientées Chunk
Une Step Chunk va être une tâche qui va se définir à travers 3 étapes : la lecture, le processus et l’écriture. Ces 3 étapes sont définies par 3 interfaces à implémenter.
- L’ItemReader qui va stocker la logique de récupération de données.
/**
* Interface à implémenter pour la Création d’un ItemReader.
* L’interface se trouve dans le package SpringBatch
* @see org.springframework.batch.item.ItemReader
*/
public interface ItemReader<T> {
/**
* Méthode qui va retourner l’élément lu.
* Cette méthode est appelée tant qu’elle retourne un objet différent de null.
*/
@Nullable
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}
- L’ItemProcessor qui va contenir la logique du traitement avec comme données en entrée ceux de l’ItemReader.
/**
* Interface à implémenter pour la création d’un ItemProcessor.
* L’interface se trouve dans le package SpringBatch
* @see org.springframework.batch.item.ItemProcessor
*/
public interface ItemProcessor<I, O> {
/**
* Méthode qui prend en paramètre un Item qui provient de l’ItemReader.
* Elle contient également la logique du batch.
* L’objet de sortie va être redirigé vers l’ItemWriter.
*/
@Nullable
O process(I item) throws Exception;
}
- L’ItemWriter qui se charge d’écrire les données en sortie de l’ItemProcessor.
/**
* Interface à implémenter pour la création d’un ItemWriter.
* L’interface se trouve dans le package SpringBatch
* @see org.springframework.batch.item.ItemWriter
*/
public interface ItemWriter<T> {
/**
* Cette méthode prend en paramètre une liste d’Objet qui sort de l’ItemProcessor.
* Il va être possible d’effectuer la logique d’écriture sur la liste passée en paramètre.
*/
void write(List<? extends T> items) throws Exception;
}
Pour ce qui est de l’ItemReader et de l’ItemWriter, il existe beaucoup d’implémentations utilisables directement dans la librairie de Spring Batch. Avant de créer une Step orientée Chunk, il est donc important de vérifier qu’il n’existe pas déjà un ItemReader et un ItemWriter qui font exactement ce que l’on veut. Lien vers une liste d’ItemReader et d’ItemWriter
Un exemple de configuration de Step :
/**
* Définit le bean correspondant à la step du batch.
*
* @param reader
* @param processor
* @param writer
* @return Step
*/
@Bean
public Step stepBatch(ItemReader reader,
ItemProcessor processor,
ItemWriter writer) {
return stepBuilderFactory.get("stepBatch")
.<Person, PersonSize>chunk(5)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
Des Steps orientées Tasklet
Le type Tasklet est une façon de faire des Steps bien plus simplement, avec moins de gestion de données. Ce type de Step existe pour permettre d’effectuer des traitements sans lecture ni écriture de données, typiquement des procédures stockées en base de données.
Pour créer une Tasklet, il faut créer un classe qui va implémenter l’interface Tasklet.
/**
* Interface à implémenter pour la création d’une Tasklet.
* L’interface se trouve dans le package SpringBatch
* @see org.springframework.batch.core.step.tasklet.Tasklet
*/
public interface Tasklet {
/**
* Méthode qui va être exécutée pour effectuer le traitement de la Step.
* @param contribution donne un accès au contexte d’exécution.
* @param chunkContext offre un espace pour stocker des données faiblement typées à travers différentes steps.
*/
@Nullable
RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception;
}
Un exemple de configuration d’une Step Tasklet :
/**
* Définit le bean correspondant à la step du batch.
*
* @param tasklet
* @return Step
*/
@Bean
public Step stepBatchTwo(Tasklet tasklet) {
return stepBuilderFactory.get("stepBatchTwo")
.tasklet(tasklet)
.build();
}
Spring Batch : autres outils
Au-delà de permettre une création simple et légère de Batch, le Framework Spring Batch nous offre un panel bien rempli d’outils ! On vous en présente quelques-uns qui vous seront certainement très utiles :)
Le JobExplorer
Le JobExplorer est une classe qui est fournie de base avec la librairie Spring Batch. Cette dernière va nous permettre d’effectuer des requêtes sur les données qui sont stockées à propos des Jobs. Il sert ni plus ni moins d’interface pour récupérer les données stockées via le JobRepository.
Voici la liste des méthodes qui sont contenues dans l’interface JobExplorer :
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobInstance getLastJobInstance(String jobName);
JobExecution getJobExecution(@Nullable Long executionId);
StepExecution getStepExecution(@Nullable Long jobExecutionId, @Nullable Long stepExecutionId);
JobInstance getJobInstance(@Nullable Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
JobExecution getLastJobExecution(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(@Nullable String jobName);
List<String> getJobNames();
List<JobInstance> findJobInstancesByJobName(String jobName, int start, int count);
int getJobInstanceCount(@Nullable String jobName) throws NoSuchJobException;
}
À travers les différentes méthodes présentes dans le JobExplorer, il est donc possible d’accéder à un historique des Jobs exécutés et de récupérer le contexte des Jobs. Si jamais vous avez besoin d’historiser l’exécution des Jobs en conservant des données spécifiques, il vous est possible de passer par l’ExecutionContext qui sera stocké dans la classe JobExecution. Il est cependant important de noter que ce n’est pas fait pour stocker des données lourdes... il faut privilégier des Objets légers et avec des variables faiblement typées !
La parallélisation des Steps
Il est fréquent que certains traitements sur des grands volumes de données soient longs. Une des solutions possibles est de paralléliser le traitement via Spring Batch. C’est assez simple à mettre en place mais, il faut faire attention... Si jamais le traitement effectué dans votre batch n’est pas parallélisable pour des questions de traitement de données en simultané, Spring Batch ne va pas vous offrir une solution-miracle !
Pour mettre en place la parallélisation au sein d’une Step, il faut spécifier le TaskExcecutor qui sera utilisé pour la Step :
@Bean
public Step stepBatch(ItemReader reader,
ItemProcessor processor,
ItemWriter writer) {
return stepBuilderFactory.get("stepBatch")
.<Person, PersonSize>chunk(5)
.reader(reader)
.processor(processor)
.writer(writer)
// Ligne à rajouter
.taskExecutor(taskExecutor())
.build();
}
@Bean
public TaskExecutor taskExecutor(){
return new SimpleAsyncTaskExecutor("spring_batch");
}
Dans le cas d’une Step orientée Chunk, une seule instance de chaque ItemReader, ItemProcessor et ItemWriter seront créés, mais plusieurs taskExecutor vont pointer vers les instances et pouvoir appeler les méthodes implémentées. Il est important que chaque étape du processus puisse supporter plusieurs appels concurrents. Si ce n’est pas le cas, pensez à rajouter synchronized lors de la définition de la méthode comme dans l’exemple suivant :
T synchronized read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
Spring Batch, notre avis ?
Pour ma part, l’utilisation de Spring Batch c’est un grand oui ! C’est vraiment un outil très pratique, voire indispensable lors du traitement de gros volumes de données en JavaLangage de développement très populaire !. Spring Batch offre de nombreux outils non négligeables lors de traitements de données et propose également une structure dans le code très appréciable pour les travaux en équipe ! Il faut aussi noter que la documentation de la librairie est très complète et va jusqu’à traiter des cas complexes, alors, si vous êtes perdu, n’hésitez pas à y faire un tour !
Notons tout de même un point de vigilance. Comme c’est le cas pour beaucoup de librairies Spring, lorsque l’on veut en faire une utilisation basique c’est très agréable et rapide... mais dès que l’on traite des cas plus complexes, il faut bien prendre le temps de comprendre le fonctionnement de la librairie car on peut facilement s’y perdre ! Aussi, lors d’un traitement très simple, comme la répartition du code est très structuré, on peut se retrouver rapidement à devoir écrire 5 fichiers pour uniquement insérer un CSV dans notre base de données... c’est desfois un peu long, mais ce petit défaut n’est rien par rapport aux possibilités de l’outil !
Vous l’aurez compris, la librairie Spring Batch est très vaste et offre plein d’outils ! Dans cet article, nous avons fait un tour des principales fonctionnalités qui existent, mais sachez qu’il existe encore plein de possibilités ! Et vous, vous utilisez Spring Batch ?
Nos podcasts en lien


Pour aller plus loin
Java Spring – Les Beans
On vous explique le cycle de vie et la configuration des beans sur Java Spring
Les tests unitaires en Java Springboot
Pourquoi et comment écrire des tests unitaires ? Définition et implémentation dans une application Java Springboot
Agent de messages (message brokers) : définition et usages
Qu’est-ce qu’un agent de message ou message broker ? À quoi ça sert ? Quels outils : plutôt Apache Kafka ou Rabbit MQ ? Le point avec des exemples sur cet article !




Nous suivre, nous écouter





