
Le RAG, c'est quoi ? La révolution de la recherche documentaire !
Dans toutes les entreprises, la recherche documentaire est un véritable défi à la fois pénible et coûteux ! Entre les différents endroits de stockage et la volumétrie des documents qui explose, difficile pour les collaborateurs de trouver ce qu'ils cherchent.Alors, comment peut-on retrouver rapidement une information précise dans une volumétrie de documents démesurée ? La solution tient en 3 lettres : le RAG (Retrieval Augmented Generation), un outil permettant d'intéragir avec tous vos documents.

Pourquoi nous faire confiance
AXOPEN est spécialisé dans les développements de projets informatiques métiers, techniques et complexes.
à propos de l'auteur

Qu'est-ce que c'est un RAG ?
Un RAG est une base de connaissances intelligente qui se source directement sur les documents que vous lui fournissez.
Et le RAG n'est pas seulement un système de stockage de documents ! Il permet d'interroger directement vos documents en leur posant des questions, et donc, de répondre à une demande d'informations précise ! C'est la sa vraie valeur, il agit comme un véritable expert de la gestion documentaire au sein de votre entreprise.
Pourquoi utiliser un RAG en entreprise ?
Les entreprises acquièrent de nouveaux documents et les accumulent à une vitesse impressionnante : rapports, documents commerciaux, documents projet, présentations, contrats, emails, photos, etc. Cette volumétrie constitue une véritable richesse pour une société, mais est souvent un frein pour votre productivité :
- Les collaborateurs perdent un temps fou à retrouver une information.
- Les documents sont stockés dans différents endroits et formats, et sont donc difficilement accessibles
- La recherche par mot-clés traditionnelle n'est pas toujours fiable, et surtout, elle nous fait passé à côté d'informations pertinentes !
Le RAG permet justement aux entreprises qui ont beaucoup de documents, de transformer les archives en base de connaissances vivante et interrogeable, et contribue à redonner du sens et de la valeur à ces documents ! Plus qu'un outil, il permet de faire gagner du temps de recherche dans des bases documentaires interminables pour vos collaborateurs.
A nos yeux, le RAG est un vrai un investissement stratégique pour les organisations qui veulent optimiser leur gestion du savoir et connaissance.
Architecture et fonctionnement d'un RAG
Le fonctionnement d'un RAG se décompose en 2 grandes parties :
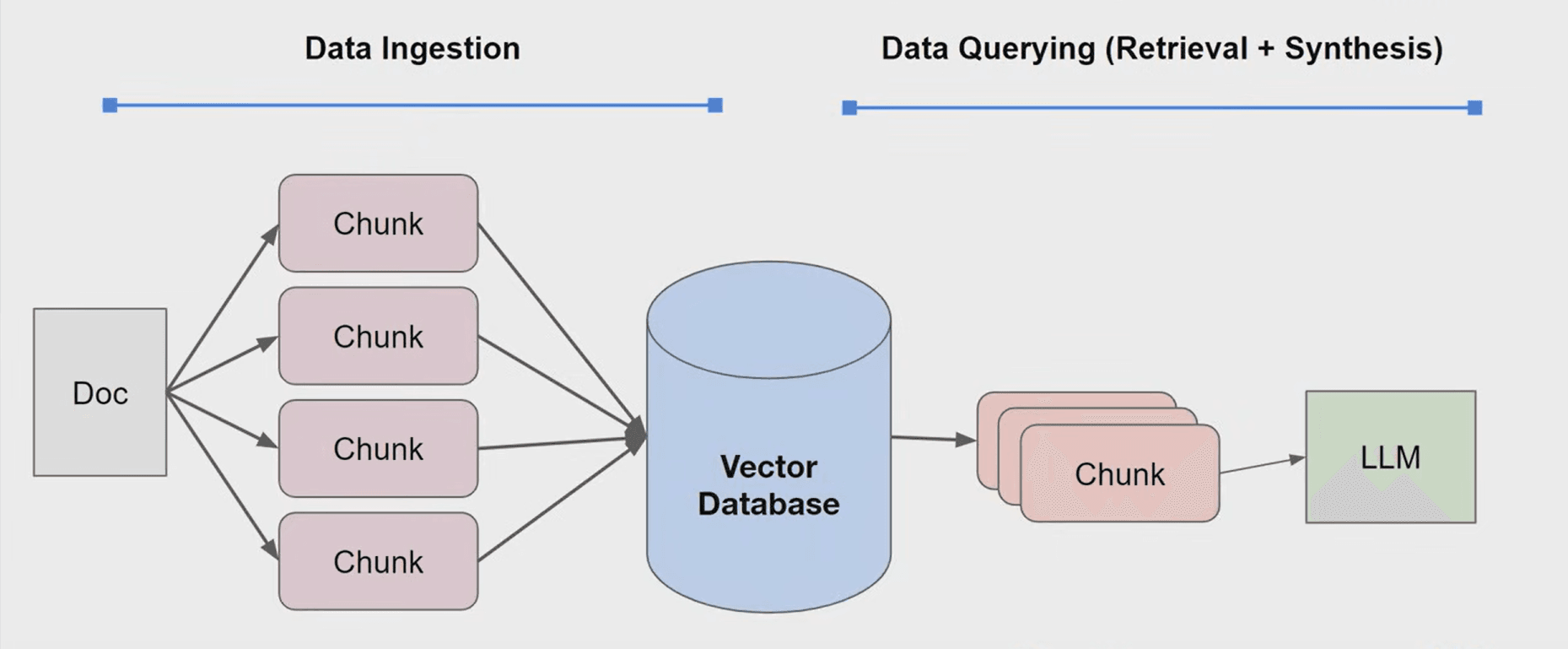
Le Data Ingestion
La première étape est la Data Ingestion, comprenez, l'ingestion des données. Cela consiste à collecter les documents d'une entreprise, quelle que soit leur nature :
- Documents PDF, Word, Excel, PowerPoint, Markdown
- Pages web et wikis internes
- Emails et communication
- Etc.
Une fois les documents collectés, le RAG va effectuer un découpage par segments : c'est ce que l'on appelle les "chunks". C'est une segmentation qui respecte la structure de vos documents afin d'en extraire seulement les partie pertinentes, tout en gardant le contexte. On peut voir ça comme un découpage intelligent de vos documents ! Les "chunks" sont ensuite stockés dans une base vectorielle.
Contrairement aux bases relationnelles qui nécessitent des requêtes structurées, les bases vectorielles permettent des recherches conceptuelles. Elles comprennent que "Java" et "Python" sont liés, même sans partager les mêmes lettres, car leurs représentations vectorielles sont proches.
Sans entrer dans les détails, on comprend que c'est l'outil parfait pour le RAG, car ça permet de retrouver tous les Chunks qui ont un "sens" proche à nos requêtes, tout ça avec du langage naturel.
Le Data Querying
Le Data Querying est composé de 2 étapes principales :
- L'appel à la base vectorielle, afin de récupérer tous les "chunks" les plus pertinents pour votre demande.
- Puis l'appel au LLM, en passant comme contexte tous les "chunks", et la demande comme prompt.
Comment optimiser son RAG ?
Le type de RAG expliqué jusqu'à maintenant peut être appelé "naïve RAG", de par son côté très simpliste. Seulement, il existe tout un tas d'optimisation qu'on peut ajouter, à toutes les étapes du processus !
Pour optimiser la Data Ingestion, vous pouvez par exemple ajouter :
- Un OCR Intelligent : pour les documents non-textuels (images, scans), une technologie OCR (Optical Character Recognition) avancée extrait le contenu textuel en préservant au maximum la mise en forme et la structure originale.
- L'enrichissement par les métadonnées : l'ajout d'informations qui donne encore plus de sens à vos "chunks" ou documents !
- Questions associées : des questions auxquelles le chunk pourrait répondre.
- Mots-clefs : de simples mots qui permettent de cibler les chunks, pour ensuite affiner la recherche afin de trouver des chunks plus pertinents.
- Relations sémantiques : des liens entre des chunks, ce qui créeront un réseau de connaissances interconnecté !
Pour la partie Data Querying, il existe aussi des solutions d'optimisations, comme par exemple, passer la demande d'abord par un LLM, afin qu'il la reformule correctement avant de l'envoyer à la base vectorielle.
Comment maintenir un RAG dans la durée ?
Comme beaucoup d'outils, le gros défi est la maintenance dans la durée des outils ! Et le RAG n'échappe pas à cette règle, puisque qu'une fois un RAG en place dans votre entreprise, vous devez maintenir vos données à jour pour que les réponses aux questions posées par vos collaborateurs dans leurs recherches soient pertinentes.
Alors, pour garantir au mieux le fonctionnement de votre RAG, on préconise souvent d'avoir des systèmes d'alimentation ou de mise à jour de vos documents de manière automatisée ! On peut imaginer des connecteurs entre votre gestion documentaire et le RAG (via APIUne API est un programme permettant à deux applications distinctes de communiquer entre elles et d’échanger des données.), avec des règles permettant de détecter si de nouveaux documents ont été ajoutés, modifiés ou supprimés automatiquement.
Aide à la mise en place d'un RAG à Lyon
Vous vous intéressez au RAG, souhaitez étudier les solutions, et mettre en place un RAG dans votre entreprise ? Chez AXOPEN, nous pouvons vous aider sur le sujet :
- Conseil dans la solution RAG à adopter
- Aide à la mise en place d'une RAG (solutions open-source et self-host pour garantir la confidentialité de vos données)
- Aide à l'intégration de vos outils IA (bedrock AWS ou Azure IA) déjà en place
- Aide à l'intégration de solutions cloud comme OpenIA, Claude, etc.
Nos podcasts en lien


Pour aller plus loin
Comment optimiser son RAG ?
Si vous êtes arrivé ici, c'est que vous avez déjà un minimum de compréhension sur les RAG : à quoi ils servent, comment ils fonctionnent et quels sont les enjeux. Si ce n'est pas le cas, je vous invite à venir découvrir cet article sur une [introduction aux RAG](/blog/2025/08/comment-fonctionne-un-rag) ! Dans cet article, on va découvrir comment optimiser un RAG, ou en clair, quels sont les leviers qui permettent à un RAG de répondre au mieux aux questions qui lui sont posées.
RAG : comment ça marche techniquement ?
Un RAG (Retrieval Augmented Generation) est un système utilisé dans les entreprises pour améliorer la gestion documentaire, et notamment, faciliter la recherche dans de grosses volumétries de documents. Si vous avez déjà testé d’utiliser l’IA avec les LLM traditionnels pour ce sujet, vous avez sûrement rencontré des problématiques importantes liées au manque de contexte ou de connaissances basé sur les documents (dû à la limite de tokens d’entrée). C’est là où le RAG joue sa carte ! Un RAG a pour but d’alimenter la base de connaissances de votre IA avec vos documents. Et comme, elle se base sur vos données pour répondre aux questions (documents internes, données confidentielles, etc), les réponses sont plus pertinentes ! Dans cet article, nous plongeons au coeur du fonctionnement d’un RAG pour vous expliquer les rouages du système. Let’s go !
JBOSS 7 retours d'expérience
Retours d’expériences sur le tout nouveau serveur jBoss 7!






Nous suivre, nous écouter




