
SEO : comment améliorer son référecement grâce au RDF ?
Le web regorge d'informations, mais encore faut-il que les moteurs de recherche les comprennent correctement. C'est précisément l'objectif de RDF : structurer les données pour les rendre lisibles, interopérables et exploitables. Derrière ce standard un peu académique se cache en réalité un levier concret pour améliorer la visibilité d'un site et renforcer sa stratégie SEO.

Qu'est-ce que RDF ?
RDF est une technologie de représentation de données dans le web qui a pour objectif d'aider au parsing et à la libre transmission des connaissances. Certes, ça peut ne pas donner envie à tout le monde, mais une saine quantité de partage peut permettre aux moteurs de recherche de comprendre ce qui se passe dans la page et ainsi fournir un avantage au référencement.
RDF : comprendre ce qui se cache derrière
RDF sert à combattre "l'anarchie" du Web : chacun fait ce qu'il veut dans sa page et réprésente ses informations comme il l'entend, ce qui entraine des difficultés à parser les documents. Le standard est théorisé par Berners-Lee en 1997, preuve que ces préoccupations sont quasiment aussi anciennes que le développement du web!
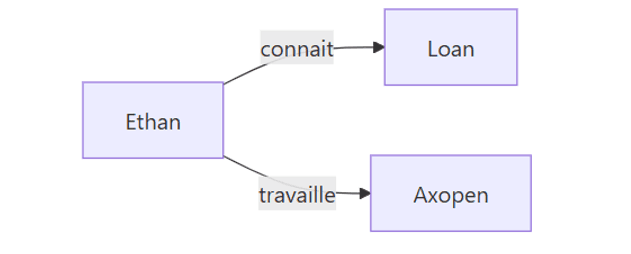
RDF, c'est une représentation de faits. Un fait, c'est un sujet, un verbe, un complément. Ethan connait Loan. Ethan travaille chez AXOPEN. Derrière ces faits, on va pouvoir construire des graphes de faits.
Dans le vocaulaire de RDF, le sujet reste le sujet, le verbe devient le prédicat (en lien avec le fait qu'on représente en logique des prédicats d'arité deux, comme connait(Ethan, Loan), regardez la logique du premier ordre pour plus d'informations), et le complément devient l'objet.
Ces trois valeurs forment un tiplet, encore appelé triple en anglais.
Derrière, une force importante de RDF est de pouvoir unir des graphes, un peu comme si un humain apprenait. Les liens restent les mêmes.
Mais pour le moment, vous avez bien du remarquer qu'Ethan était juste un prénom : comment représenter une ressource unique sur internet? C'est là qu'on est sauvés par les standards du web. On va tout représenter par des URLUniform Ressource Locator. Ethan devient https://pegeot-kaiser.fr, le verbe "connaître" deviendra http://xmlns.com/foaf/0.1/#knows.
Tout? Bien évidemment que non, les objets peuvent rester des strings, des nombres, des dates (des objets atomiques).
Deux choses à noter qui nous seront utiles pour la suite : les ontologies, et les préfixes. Les préfixes sont un raccourci pour représenter le début d'une URL : par exemple, on pourra écrire "foaf:" au lieu de "http://xmlns.com/foaf/0.1/", ce préfixe est défini en haut des requêtes et certains d'entre eux sont suffisament standards pour être inclus par défaut dans certains moteurs.
Les ontologies représentent des vocabulaires : un ensemble de verbes auxquels on a donné un sens. Par exemple foaf:knows représente la notion de lien. Certaines ontologies sont plus poussées, et utilisent la surcouche RDFs pour représenter des "classes" et ainsi fournir un système plus évolué.
Comment se servir de RDF pour amméliorer son référencement?
Commençons par voir comment implémenter du RDF dans un site avant de voir comment s'en servir : les avantages sauteront aux yeux une fois que l'on aura vu la facilité d'implémenter le système.
Il existe plein de manières d'incorporer des métadonnées dans ses pages, Google décrit notamment ici les différents système qu'il sait indexer.
Nous allons nous focaliser sur trois d'entre eux :
- RDFa, un système "ancien" mais qui montre bien l'intégration au sein d'une page web
- Les microdatas, la version "cachée" la plus courante d'utilisation de RDF
- L'intégration de JSON-LD dans les pages
RDFa, l'ancêtre qui montre bien comment exploiter l'existant pour faire du RDF
Dans RDFa, l'idée est de représenter des faits en s'appuyant sur la structure du document HTMLHTML (HyperText Markup Language) est un langage permettant de décrire le découpage d'une page web. existante.
<p prefix="dc: http://purl.org/dc/elements/1.1/"
about="http://www.example.com/books/wikinomics">
Dans son dernier livre
<em property="dc:title">Wikinomics</em>,
<span property="dc:creator">Don Tapscott</span>
explique les profonds changements technologiques, démographiques
et économiques.
Ce livre a été publié en
<span property="dc:date" content="2006-10-01">octobre 2006</span>.
</p>
Dans cet exemple issu de Wikipédia (https://fr.wikipedia.org/wiki/RDFa), on peut voir un paragraphe comme on pourrait en avoir plusieurs sur le site, agrémenté de différentes données exprimées sous forme de triples. Ainsi, vous voyez qu'on définit des préfixes à l'échellle du paragraphe, puis qu'on définit que le sujet du paragraphe sera "http://www.example.com/books/wikinomics". Les différents verbes sont introduits par "property" et les objets sont le contenu de la balise HTML.
Microdatas
Vous connaissez déjà certainement microdata ! La plupart les programmeurs ont déjà défini une fois ces métadonnées qui permettent un "joli" affichage d'un lien dans une appli de messagerie.
Par exemple, Axopen définit sur son site :
<meta property="og:url" content="https://www.axopen.com/">
<meta property="og:title" content="Axopen - Expertise et développement informatique">
<meta property="og:description" content="Axopen offre des services d'expertise et de développement informatique. Découvrez nos solutions innovantes. Contactez-nous pour en savoir plus sur nos services.">
Maintenant que vous avez le contexte, vous aurez peut-être remarqué le préfixe "og:" qui représente l'ontologie de l'Open Graph Protocol Dans ce système, le sujet est toujours la page reqûetée (les métadonnées servant en effet à parler de cette page) et l'objet la valeur de "content".
JSON-LD, la pleine puissance des classes
JSON-LD est un standard de représentation des données ouvertes extrêment puissant, et aussi utilisé en dehors de RDF (pour lequel il avait été inventé en 2010), par exemple avec APIUne API est un programme permettant à deux applications distinctes de communiquer entre elles et d’échanger des données. Platform qui propose par défaut des outputs en JSON-LD.
Ainsi, il est possible de s'intéresser aux classes définies par schema.org comme Organization ou encore Person qui représentent une entreprise et une personne respectivement. Le vocabulaire utilisé est facilement liable à d'autres ontologies existantes.
Pour reprendre un exemple de bonnes pratiques, Axopen définit :
<script type="application/ld+json" id="websiteJsonLD">
{
"@context": "http://schema.org",
"@type": "WebSite",
"name": "Axopen",
"alternateName": "Axopen Innovative Solutions",
"url": "https://www.axopen.com"
}
</script>
L'attribut @context définit le préfixe utilisé dans ce document. @type est une annotation en lien avec RDFs, que je ne couvrirai pas mais qui représente un système de classes interchangeables.
Les autres propriétés sont les attendus de la classe "WebSite".
Comment exploiter toute cette technologie?
Comme vous avez pu le voir, il est extrêment simple d'intégrer du RDF à ses documents existants. La bonne nouvelle est qu'il est donc tout aussi simple d'extraire des données représentées par RDF. La méthodologie est simple : récupérer le document, identifier les attributs qui nous intéressent (des scripts en JSON-LD, des attributs HTML avec la mention "property", etc...) avant de stocker les triples dans un triplestore.
Les triplestores sont des bases de données plus ou moins optimisées pour le traitement de triplets RDF. Ma recommandation est d'utiliser Apache Jena et son serveur web Fuseki. Il est possible de requêter le triplestore à l'aide de SPARQL pour extraire les informations utiles dans le graphe. Le langage à une syntaxe proche du SQLLangage permettant de communiquer avec une base de données. et est facile à prendre en mains. Un bon outil pour apprendre la syntaxe et s'y essayer est d'aller sur DBPedia, une représentation des données de Wikipedia en RDF.
Pourquoi utiliser RDF pour son référencement?
RDF permet aux moteurs de recherche de facilement extraire des informations utiles, ce qui vous confère instantanément un bonus en terme de SEO. Mettre en oeuvre du RDF est simple à faire et peut s'automatiser facilement avec l'aide d'une équipe spécialisée (à tout hasard comme AXOPEN).
Il vous est aussi possible dans l'autre sens d'exploiter des données déjà ouvertes dans vos processus, en utilisant RDF comme une façon plus reliable d'exploiter des données que vous auriez scrappées sinon.
Si vous cherchez à améliorer votre SEO, n'hésitez pas à nous en parler !
Nos podcasts en lien


Pour aller plus loin
Les applications mobiles au service des entreprises
Aujourd’hui, la mobilité est un des principaux investissements IT des entreprises. Et pour cause, l’utilisation des smartphones et des tablettes est de plus en plus répandue. Seulement l’investissement en mobilité des entreprises n’est pas uniquement con
Les pires choses qui peuvent arriver à un dév
Découvrez la planche #36 !
Comment comparer 2 schemas Mysql ?
Qui n’a jamais eu le besoin de comparer 2 schemas de base de données Mysql après avoir oublier de noter l’ensemble des modifications apportées à un environnement ?




Nous suivre, nous écouter




